
References
- 大模型推理加速与KV Cache(一):什么是KV Cache
- [FIXME][EP02][直播版] vllm源码讲解,分布式推理
- [FIXME][EP05][直播版] vllm从开源到部署,Prefix Caching和开源答疑
- CacheBlend-高效提高KVCache复用性的方法
Distributed Inference
具体的通信代码可以参考:vllm/model_executor/models/llama.py
分布式通信手段
- nvlink
- InfiniBand
- RDMA
并行方式
TP(Tensor Parallel):
将 tensor 拆分运算,然后通过
all-reduce/all-gather汇总。例如 LLM 的Decoder采用多头注意力(multihead-attention),假设有个头部, 张卡,则可以每张卡 个头部并行计算。 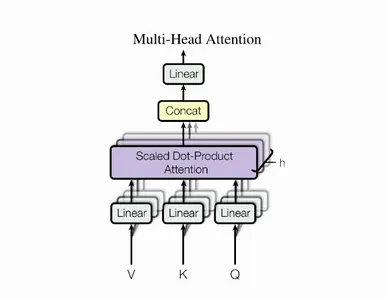
# llama前向传播的代码 def forward( self, positions: torch.Tensor, hidden_states: torch.Tensor, ) -> torch.Tensor: qkv, _ = self.qkv_proj(hidden_states) q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1) q, k = self.rotary_emb(positions, q, k) attn_output = self.attn(q, k, v) output, _ = self.o_proj(attn_output) return outputPP(Pipeline Parallel):
一个 request 由多个 node 流水线式地执行。可以提高吞吐,但是无法降低
TTFT。每个worker负责一个layers的子集
vllm/model_executor/models/llama.py中 self.start_layer –> self.end_layer- 在 worker 之间:
communicate IntermediateTensor vllm/worker/model_runner.py: 搜索get_pp_group()
EP(Expert Parallel):
用于 MoE(Mixture of Expert)架构。在处理一个 request 的时候,只有一个很小的专家子集会被激活(通过门控控制)。router 会将 request 转发到相应的 expert 节点(MoE 的前置计算可能不是在相应的 expert 节点上进行的)。这里多个 expert 是并行的,同时计算不同的 batch。
- Shuffle (DeepEP communication kernel)
- Forward
- Shuffle back
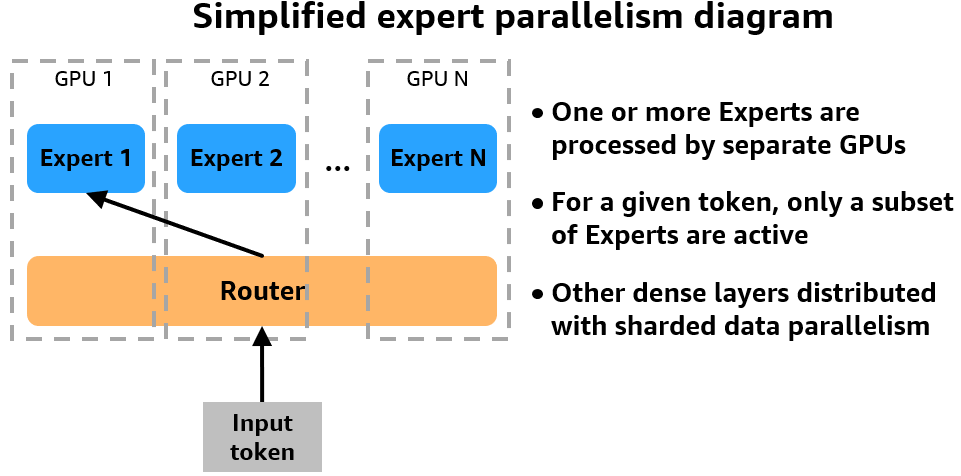
DP(Data Parallel)
因为大型分布式生产环境中,EP >> TP(attention head 可能就十几个,而 experts 可能有几百个),这时候就需要 data parallel。
- TP * DP == EP(通过请求并行的方式去拉满计算资源)
- 在实践中难以应用。
- 对请求进行padding避免造成死锁。
Prefix Caching
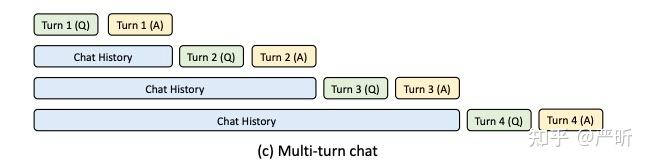
预备知识:
- LLM 的
Prefill阶段:当用户输入一个 prompt(例如 “Hello, how are”),模型会一次性处理整个输入文本,计算所有输入 token 的隐藏状态。这个阶段通常是并行计算的,效率较高;LLM 的Decode阶段:模型从第一个生成的 token 开始,逐个预测后续的 token(例如 “you”、”today” 等)。每个新 token 的生成都依赖于前一个 token。 - 在多轮对话中,需要传递上下文,这些上下文总是共享一个前缀,如上图所示。显然,我们可以缓存这些前缀对应的 KV tensor,这也就是
Prefix Caching,缓存的对象便是K和Vtensor。 Prefix Caching只节省了Prefill阶段的耗时(也就是降低了TTFT,Time To First Token),并不能节省解码阶段的耗时(也就是TPOT,Time Per Output Token)。
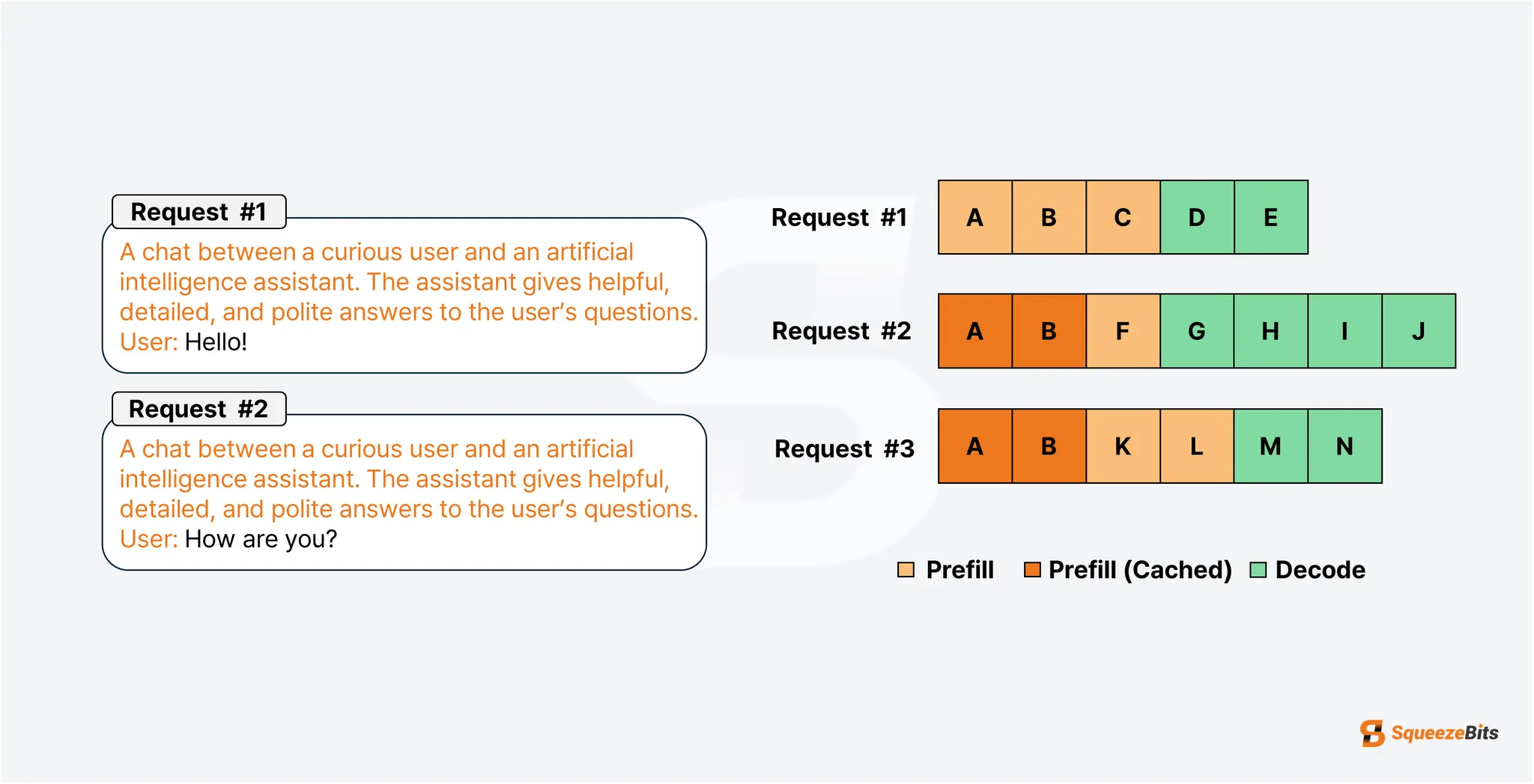
vllm 中的 Prefix Caching 主要思路:
- 将若干个
tokens(默认 16 个)组成一个block,对于每个block,计算其 hash 值并更新prefix hash。 - 将
prefix hash->kv cache的映射存储到kv store中(例如 redis,注意后者的kv指的是键值存储)。 - 若无法
allocate缓存空间,以一定的策略(如 LFU,LRU)evict 一些缓存。
伪代码:
prefix_hash = ""
for chunk in chunked_token:
chunk_hash = hash(prefix_hash + chunk)
prefix_hash = chunk_hash
for chunk_hash, chunk_kv in zip(...):
kv_store.put(chunk_hash, chunk_kv)
Prefix Caching 的扩展——CacheBalend
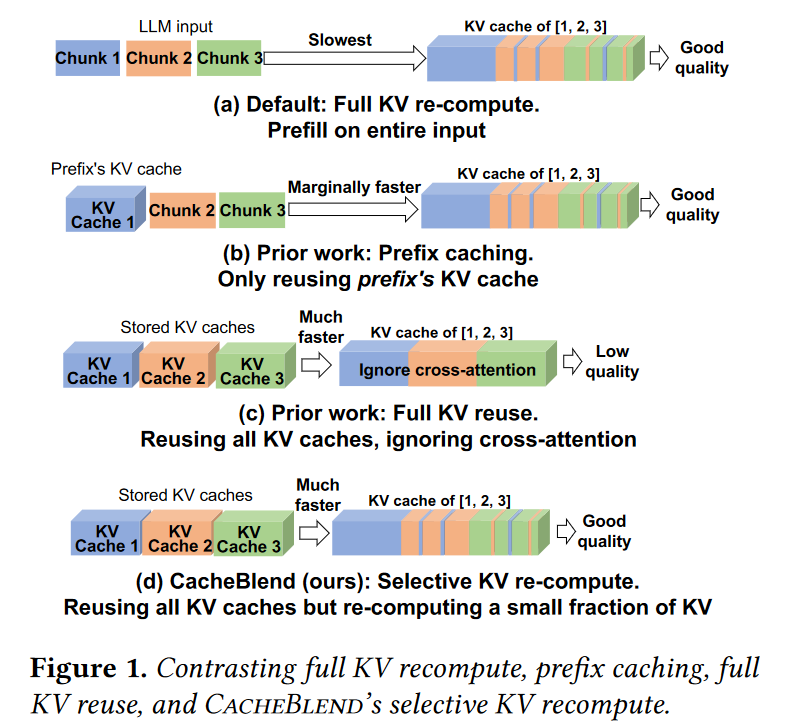
- Prefix Caching 只利用了前缀,缓存利用率有限;
- Full KV Cache 使用所有的 Cache,会忽视
cross attention,产生低质量结果; - CacheBlend 通过重新计算一部分 KV,进行折中。
以下是忽视 cross attention 的结果:
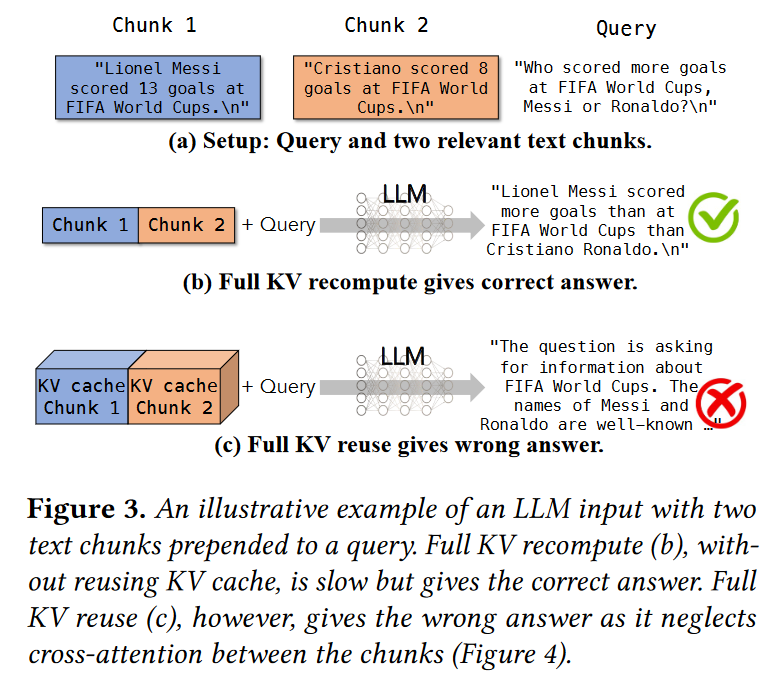
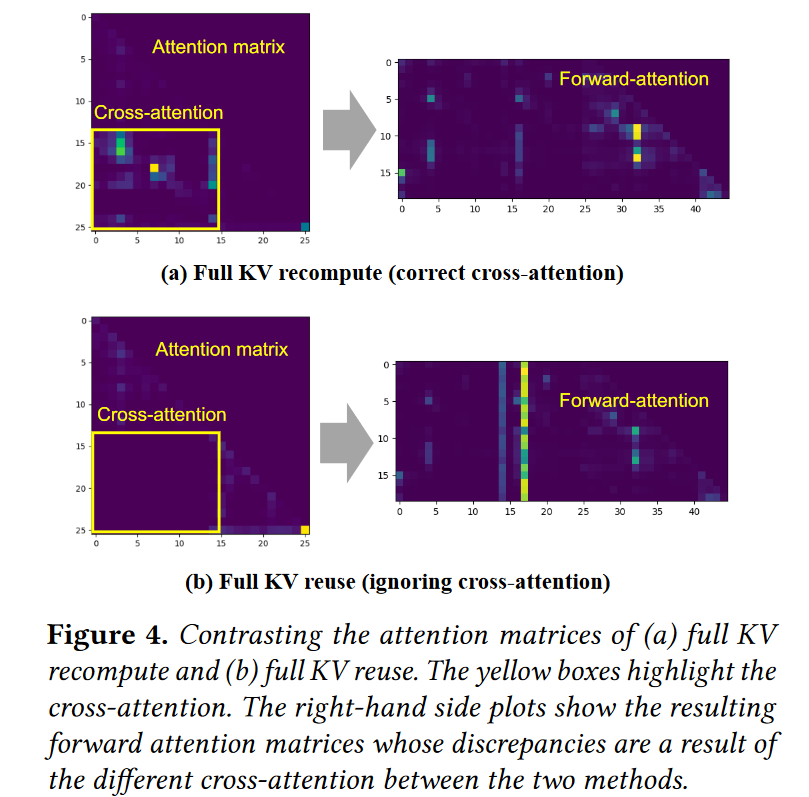
PD 分离
为什么需要 PD 分离?
在大模型推理中,常用以下两项指标评估性能:
TTFT(Time-To-First-Token):首 token 的生成时间,主要衡量 Prefill 阶段性能。
TPOT(Time-Per-Output-Token):生成每个 token 的时间,主要衡量 Decode 阶段性能。
当 Prefill 和 Decode 在同一块 GPU 上运行时,由于两阶段的计算特性差异(Prefill 是计算密集型,而 Decode 是存储密集型),资源争抢会导致 TTFT 和 TPOT 之间的权衡。例如:若优先处理 Prefill 阶段以降低 TTFT,Decode 阶段的性能(TPOT)可能下降。
若尽量提升 TPOT,则会增加 Prefill 请求的等待时间,导致 TTFT 上升。
PD 分离式架构的提出正是为了打破这一矛盾。通过将 Prefill 和 Decode 分离运行,可以针对不同阶段的特性独立优化资源分配,从而在降低首 token 延迟的同时提高整体吞吐量。
Prefill 和 Decode 阶段分别受限于什么?
Prefill 阶段:吞吐量随 batch size 增加逐渐趋于平稳。这是因为 Prefill 的计算受限特性(compute-bound),当 batch 中的总 token 数超过某个阈值时,计算资源成为瓶颈。
Decode 阶段:吞吐量随 batch size 增加显著提升。由于 Decode 阶段的存储受限特性(memory-bound),增大 batch size 可提高计算效率,从而显著增加吞吐量。
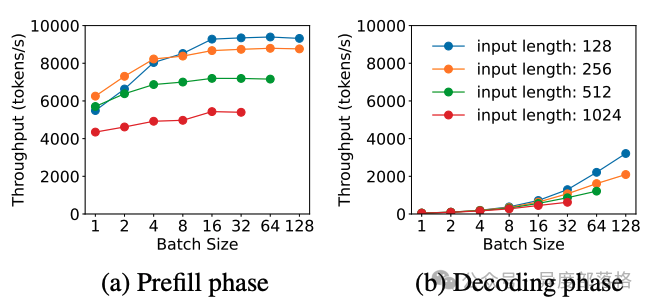
摘自 LLM推理优化 - Prefill-Decode分离式推理架构
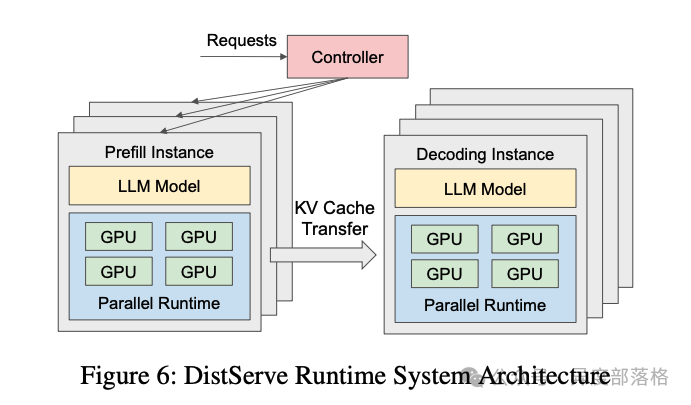
- Chunked Prefill
- xP yD 问题,Prefill Instance 和 Decode Instance 的数量如何调整?
- 先 D 后 P 的模式:D node收到后先检查是否有 KVCache,没有的话再转给 P node去做,这个思路主要考虑的是
TTFT。
传递 KV Cache
两种模式:pooling 模式,P2P 模式,LMCache都支持上面两种模式,Mooncake(pooling),NIXL(p2p)。
怎么从 vllm 提取(注入)KVCache
connector APIinvllm/worker/model_runner.py。- 在模型
forward前:尝试接收 KVCache 并注入到到 vllm 的 pages memory 中。 - 在模型
forward后,将 KVCache 从 pages memory 中并将它发送出去。
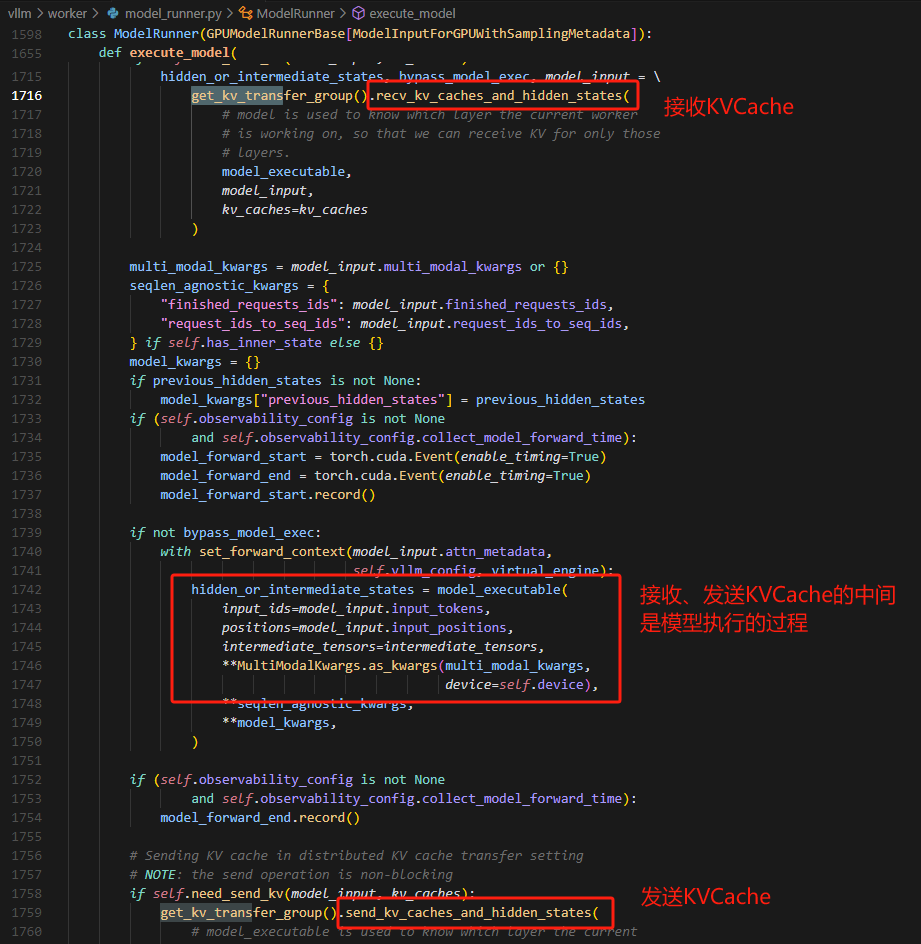
vllm/distributed/kv_transfer/kv_transfer_agent.py# 本质上是根据 model input 计算出 KVCache 放在 page memory中的什么地方 def recv_kv_caches_and_hidden_states( self, model_executable: torch.nn.Module, model_input: "ModelInputForGPUWithSamplingMetadata", kv_caches: List[torch.Tensor] ) -> Tuple[Union[torch.Tensor, IntermediateTensors], bool, "ModelInputForGPUWithSamplingMetadata"]: return self.connector.recv_kv_caches_and_hidden_states( model_executable, model_input, kv_caches)可以先看
vllm/distributed/kv_transfer/kv_connector/simple_connector.py。
Speculative Decoding
前文提到 Prefill 是 gpu-bound,计算密集型(把 request 的 tokens 全部输入 llm,生成第一个 token,并构建 KVCache);而 Decode 是 memory-bound,依赖 Prefill 阶段生成的 KVCache,访存的时间往往大于计算的时间。那么有没有一种方法可以在不怎么增加 memory access 的前提下,提升计算的吞吐呢?有的,兄弟,有的,Speculative Decoding。
Speculative Decoding 干了什么?其实就是去根据输入猜接下来的若干个 tokens 是什么,然后并行地进行验证。假如猜测 3 个 tokens,我们并行地验证这 3 个 tokens 是否正确的,由于是并行的,我们差不多只花费了原来只生成 1 个 token 的时间,最终获得了 3 个 tokens,也就是将吞吐提升了 3 倍,而访存只增加了(3 - 1)* token size。
那么如何猜呢?其实用一个古老的方法,n-gram 就行了。
An n-gram is a sequence of n adjacent symbols in particular order. The symbols may be n adjacent letters (including punctuation marks and blanks), syllables, or rarely whole words found in a language dataset; or adjacent phonemes extracted from a speech-recording dataset, or adjacent base pairs extracted from a genome. They are collected from a text corpus or speech corpus.

也就是说,我们根据一定的前缀,就能大致猜出后续的 token 搭配。Speculative Decoding 会根据输入构建 ngram,然后猜测后续的 tokens。
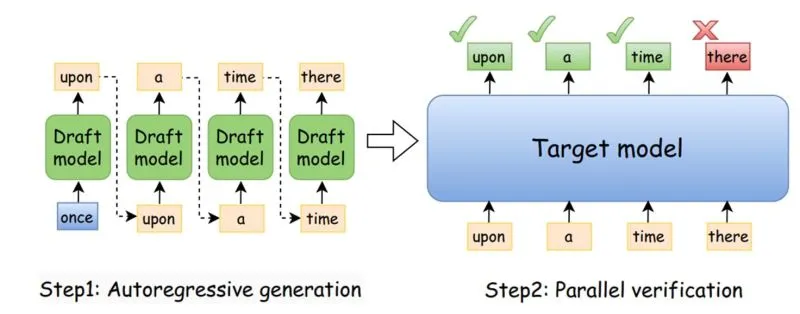
为什么这是有效的呢?下面几个 workload 就能说明这个问题:
- 全文搜索,在用户给定的内容中寻找内容,或者给出一定答案。此处的回答一定是和用户内容强相关的,本质上会复读一部分;
- 代码生成场景,变量名、函数名等都很容易被
ngram预测。
Tree Verification
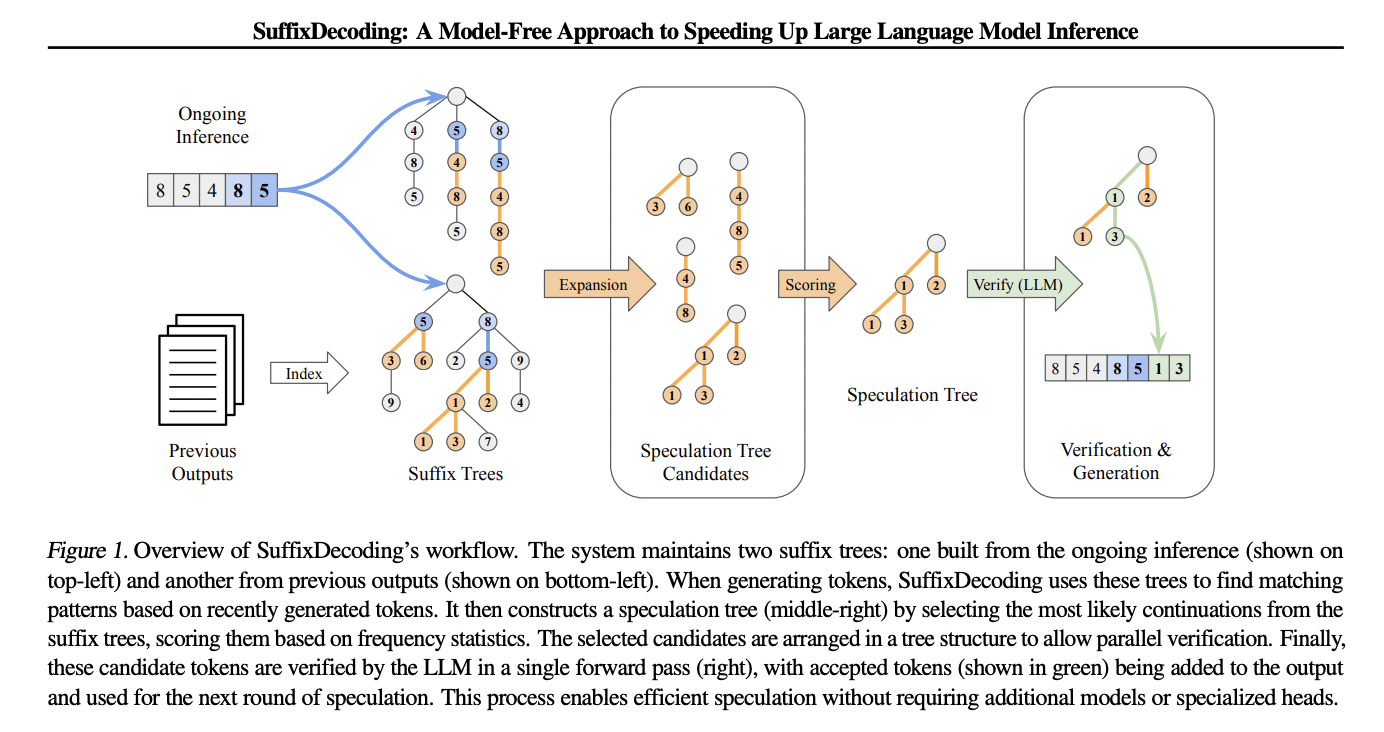
Model-based(draft model)Speculative Decoding
Parallel guessing(并行猜测)
- 优点:快,在不知道第一个 token 情况下直接猜第二个。
- 缺点:在猜测第二个 token 的时候不知道第一个token是什么,容易胡言乱语
Autoregression guessing(自回归猜测)
- 优点:在猜测第二个 token 的时候知道第一个 token,准确率较高
- 缺点:慢