
在线讲解:[Paper Reading] FoundationDB:开源分布式 KV 存储的内部实现原理
最近看 DeepSeek 的 3FS 的时候发现他们会用 FoundationDB 做 chunk metadata 的存储(3FS 有点像 GFS,也是以 chunk 作为存储单位)。正好不久之后要去阿里云开始一段存储相关的实习,学习一下相关知识。
FoundationDB 是一个分布式 KV 存储数据库,适用于读多写少的场景,支持 SSI(Serializable Snapshot Isolation)级别的事务。
FoundationDB 如何实现 SSI
SSI 这一级别是通过 OCC + MVCC 实现的。
首先,让我们复习一下事务隔离级别,可以从这篇文章切入:事务隔离级别备忘。通过 MVCC 的快照,我们可以很容易地实现 Snapshot Isolation,虽然这解决了脏读和幻读的问题,但是无法解决两种问题(也就是上面链接中的 P4 和 A5B 问题)。
P4 Lost Update

T2 修改 x 为 120,然而 T2 提交后被 T1 提交的修改覆盖,最终 x = 130。对外界而言,x = 120 这一修改不可见,被覆盖。
A5B Write Skew
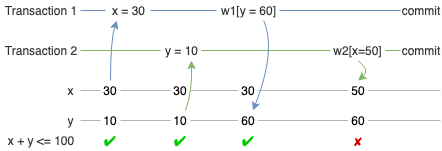
x + y 应该满足约束
x + y <= 100,由于 T1 和 T2 的write set没有相交,所以两个事务都能提交成功,然而约束已经被破坏。
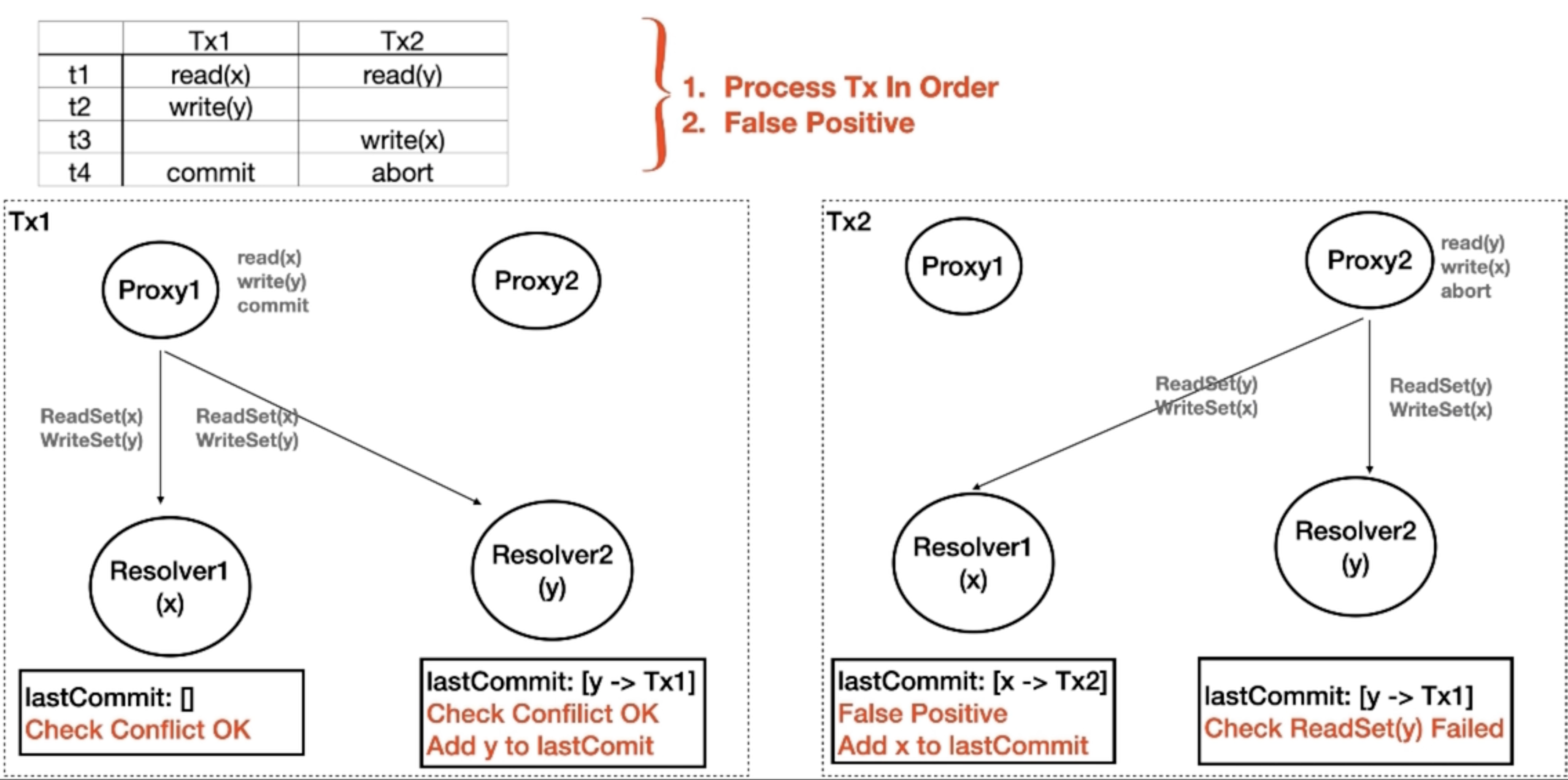
为了解决上述问题,FoundationDB 会维护一个 read set,如果 read set 中的某个 key range 对应的最新的一次 commit version 大于事务的 read version,就会 abort 当前事务。这种乐观的方式有若干好处:
- 无需锁,高效;
- 读多写少,abort 是小概率事件。
在 FoundationDB 中,resolvers 会保留最近一段时间(如 5 秒,MVCC window)内已提交的写入操作在内存中,这个时间范围就可以看作是一个 “窗口”。当一个新的事务进行冲突检测时,会将其读取的数据与这个窗口内的写入操作进行比较,以确定是否存在数据冲突。如果在这个窗口内,事务读取的数据被其他事务修改了,那么就会检测到冲突,该事务可能会被中止或重试。
FoundationDB 的架构
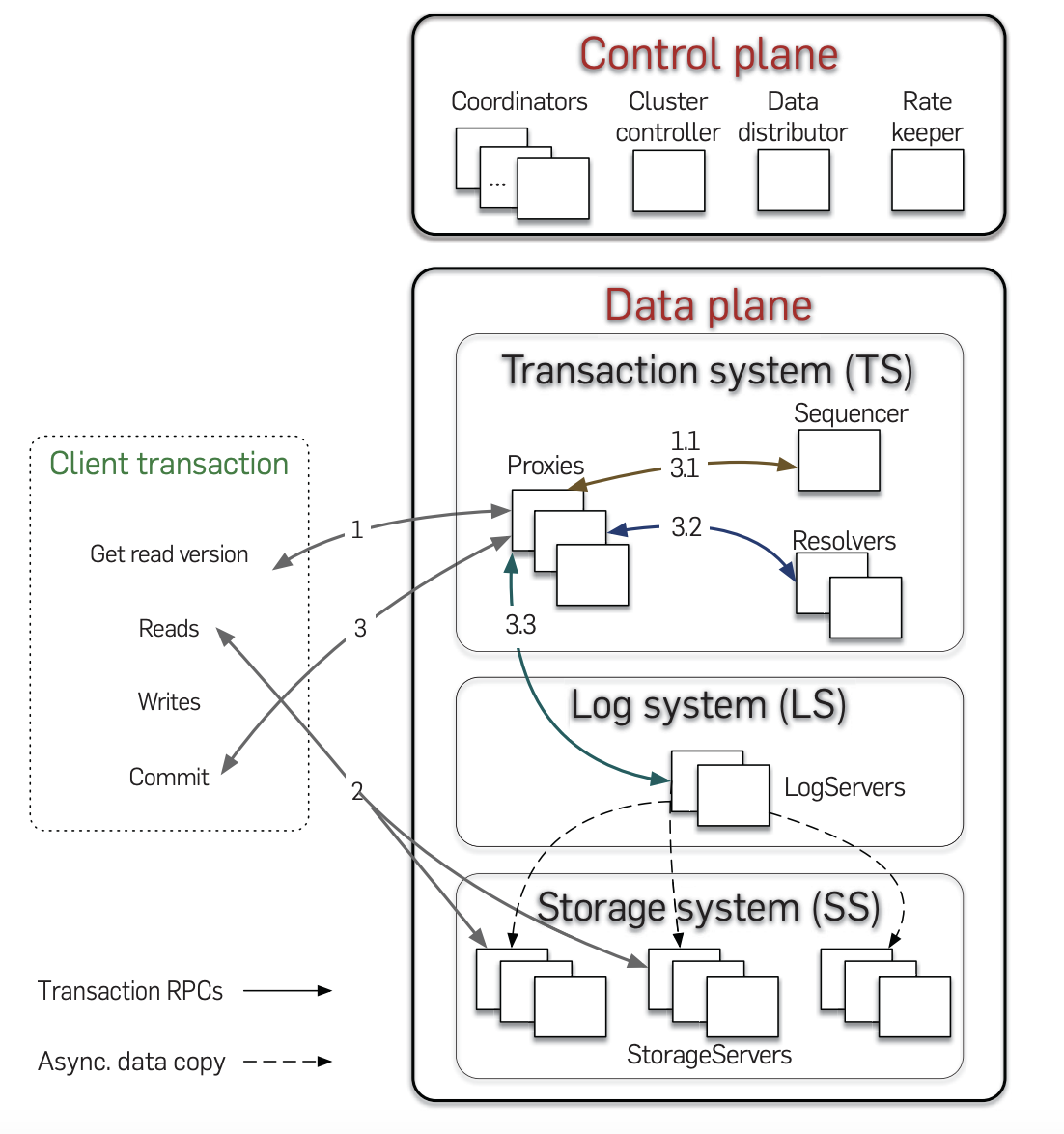
整个系统是自上而下启动的。FoundationDB 的控制面是通过 Paxos 算法选举出 Cluster Controller(即 leader),如下图所示。
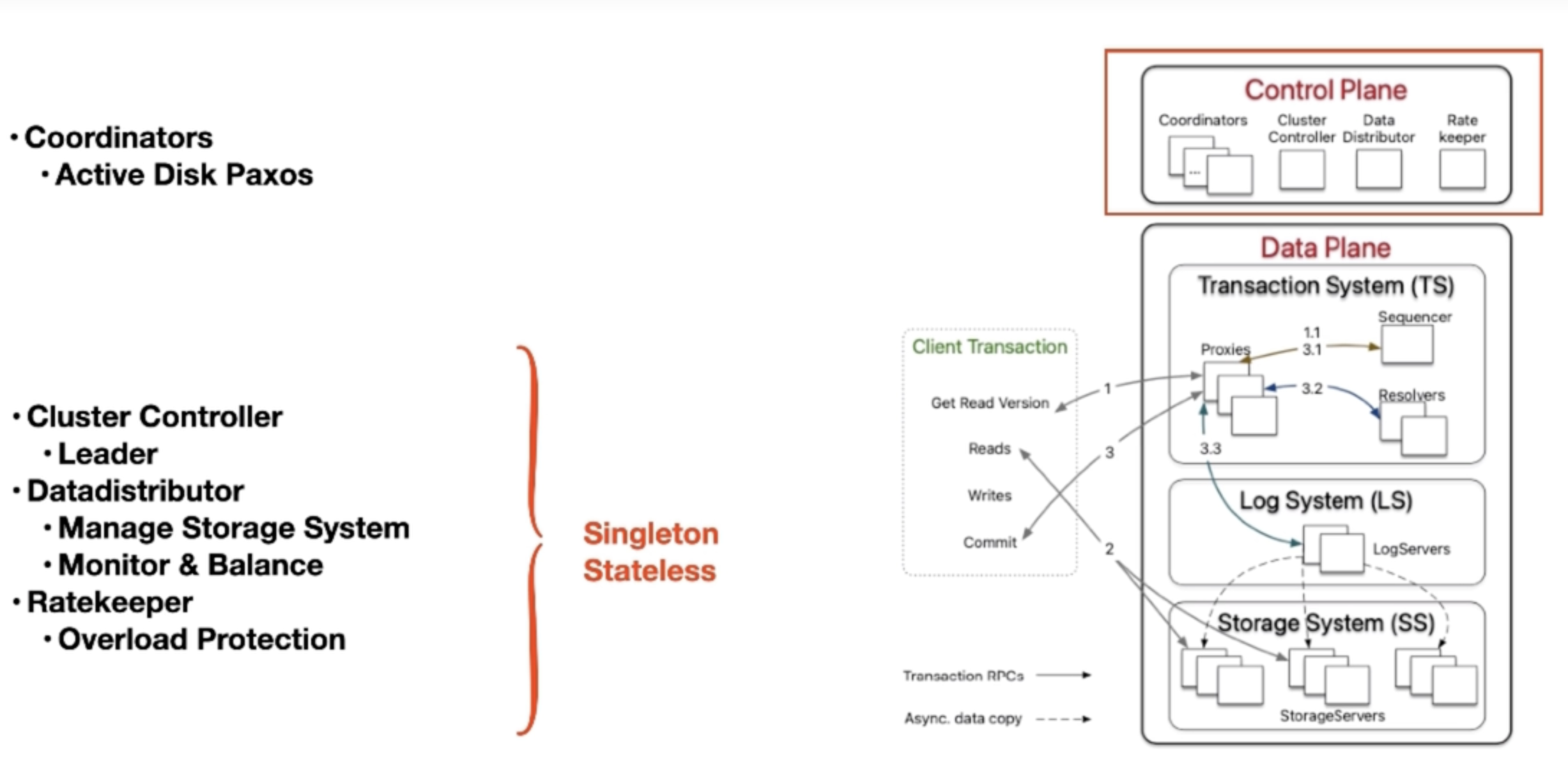
下图为数据面,主要由 TS + LS + SS 组成。
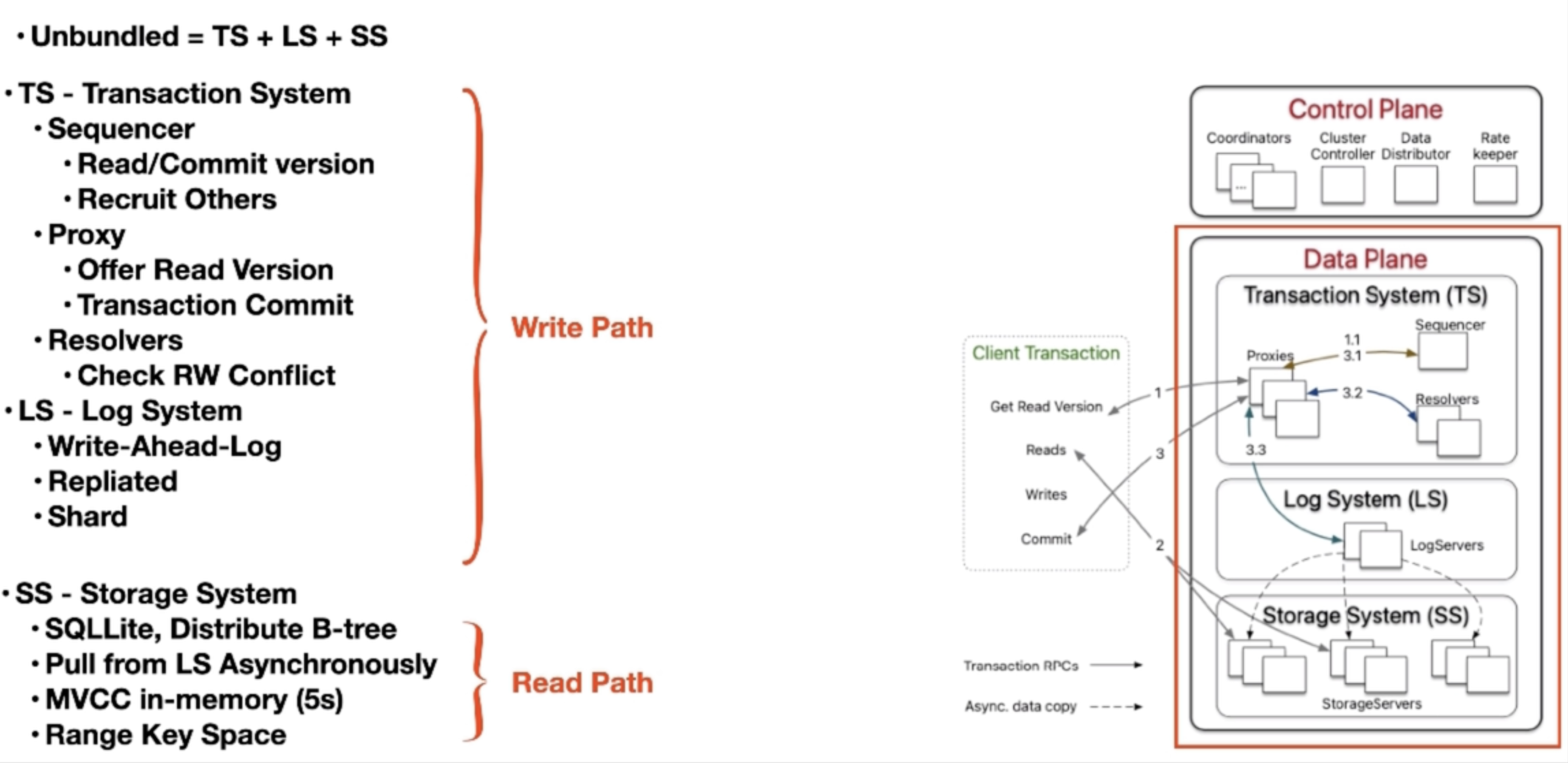
TS
- Sequencer:
- 负责获取 read/commit version。
- Proxy:
- 一个中介,负责获取 read version 和事务提交。
- Resolver:
- 分布式地解决读写冲突。
- 多节点,按照
key range分片(shard)。
LS
- 按照
key range分片(shard)。
SS
- 单机存储系统,从 LS 的 WAL 异步复制数据。
- 多版本数据只存储在内存中
- 5s 的 MVCC window(太长了会产生大量假阳性)
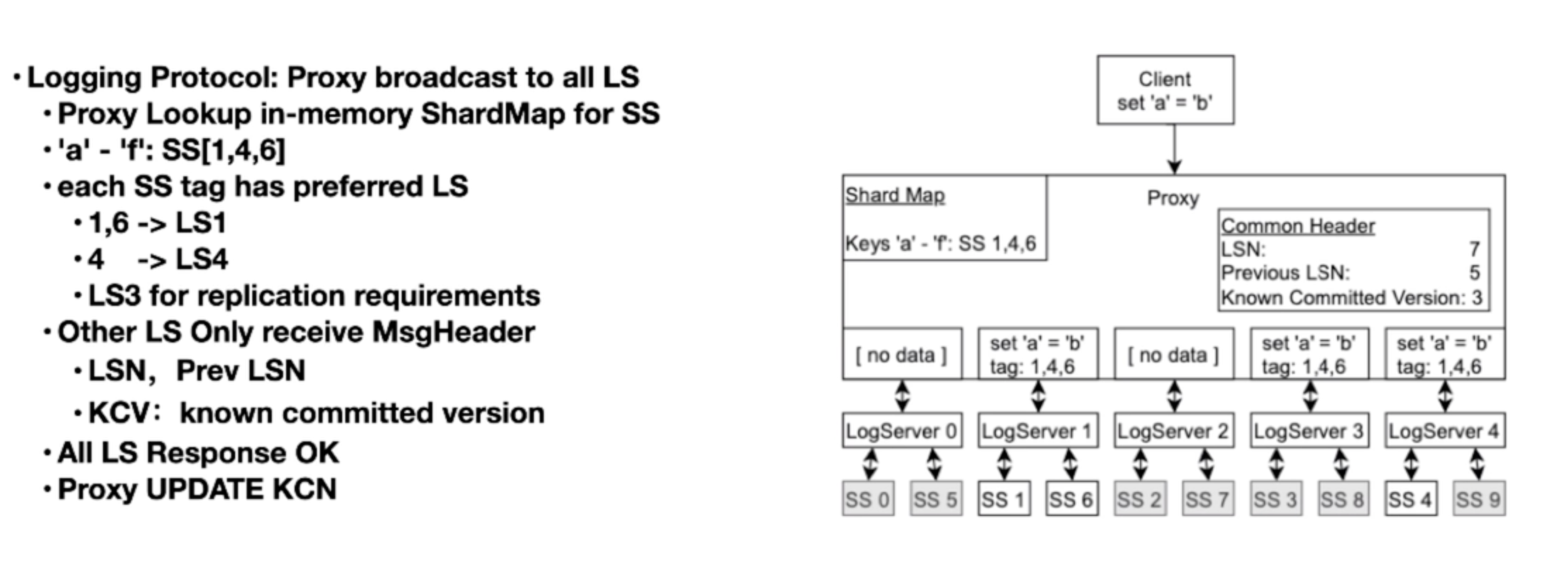
Log System
- Log Server 下面绑了若干 Storage Server。
- 按照 key range 映射到若干个 replica。
- 之所以需要向未被映射到的 Log Server 传递空消息,是因为 Log Server 是按照顺序执行的,不这样做会产生“空洞”。
Commit Path
- Client:
- Buffer Modifications
- Send Read/Write Set To Proxy
- Proxy: Get Commit Version from Sequencer
- Proxy: Send User Data KeyRange To Resolvers
- Resolver: Check RW Conflict
- Proxy: Commit Phase When no Conflict
- Send Data to LS
- Committed When All LS return Success
- Send Commit Version to Sequencer for Read
- Proxy return OK to Client
- SS pull WAL from LS
Read: 1 roundtrip
Write: 4 roundtrip
Recovery && Replication
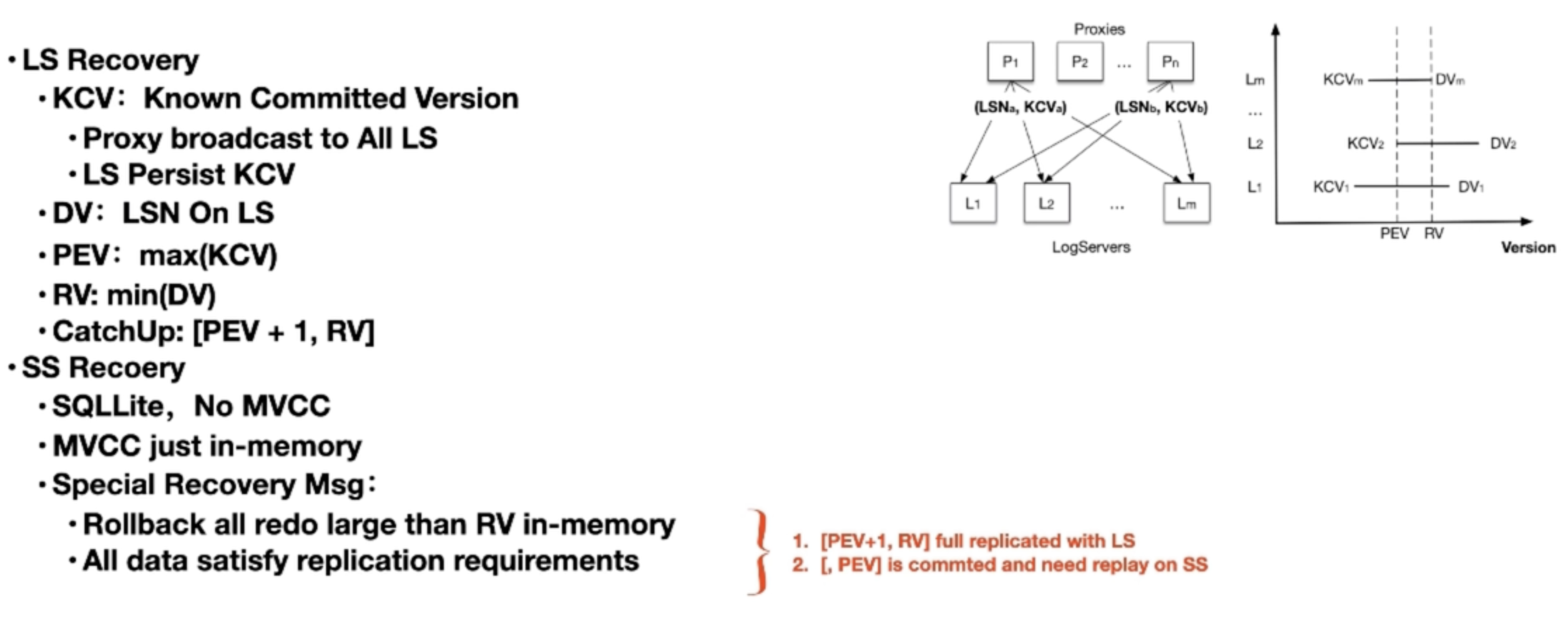
k = f + 1
这里 k 表示需要复制的日志份数,f 表示系统可容忍的故障节点数。即需要复制的日志份数比可容忍的故障节点数多 1,通过这种方式来保证即使部分节点故障,日志信息也不会丢失,能维持系统的正常运行和数据一致性。