
对应课程
Buffer Pool
Buffer Pool 需要有一个页表记录哪些页被缓存在内存中,同时需要跟踪页的使用情况(例如是否被修改?被访问过几次?)。当一个页面被使用的时候,我们应该更新它的访问记录,增加它的 pin count(类似 reference cnt,当 pin count = 0 的时候我们才可以将一个页标记为 evictable)。当一个页被驱逐的时候,如果它是脏页,我们还需要将其 Flush 到磁盘。

Latch & Lock
- Lock: 高级层次、逻辑上的锁,比如事务锁。
- Latch: 数据库内部数据结构的锁。
Page Directory & Page Table
- Page Director:持久化在磁盘中,将 page id 映射到磁盘中对应页的位置。
- Page Table:存储在内存中,将 page id 映射到 frame id。
Buffer Pool Optimization
Multiple Buffer Pools
- 使用多个 Buffer Pool 以减少 latch 竞争。
- 将 page id 映射到某个 Buffer Pool。
Pre-fetching
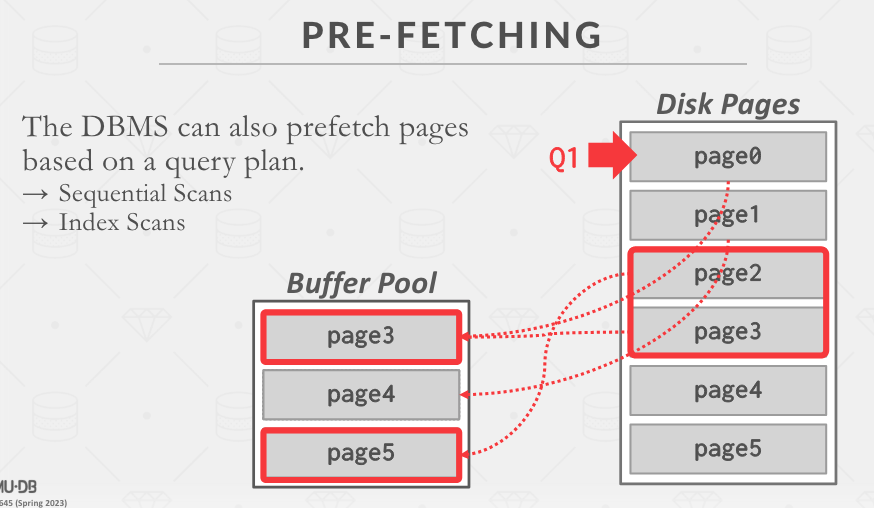
当执行某些扫描操作的时候,DBMS 可以进行预取操作,提前将未来可能读到的数据页加载到内存中。
数据库清楚自己的数据结构和语义,可以对 B+ 树上的范围查询进行预取。

Scan Sharing
当 DBMS 发现多个查询实际上是等价的时候,就可以将多个查询绑定到单个 cursor 上。查询的结果不一定要一样,还可以共享中间结果。
Buffer Pool Bypass
“Light Scan”。
顺序扫描之类的操作可能会污染 Buffer Pool,如果使用 Buffer Pool Bypass 将不会存储顺序扫描获取的页,而是保存到 worker 本地(不和其他 workers共享)。对于需要大量扫描的操作而言有效。
Bypass OS Page Cache
大多数的 DBMS 都使用 O_DIRECT 绕过 OS Page Cache,直接操作文件 I/O(这样 OS 就不会生成缓存,数据库自己来管理缓存)。

页面驱逐算法
LRU
Clock
LRU 的近似算法。
- 访问一个页面:将该页面对应的位设置为 1;
- 按照一定顺序(顺时针/逆时针)遍历,将位为 1 的设置为 0,将原先就是 0 的页面驱逐。
LRU-k
LRU 和 Clock 算法都存在的问题是它们只考虑了页面被访问的时间,但是没有考虑页面被访问的频率,很容易被 sequential flooding 污染。
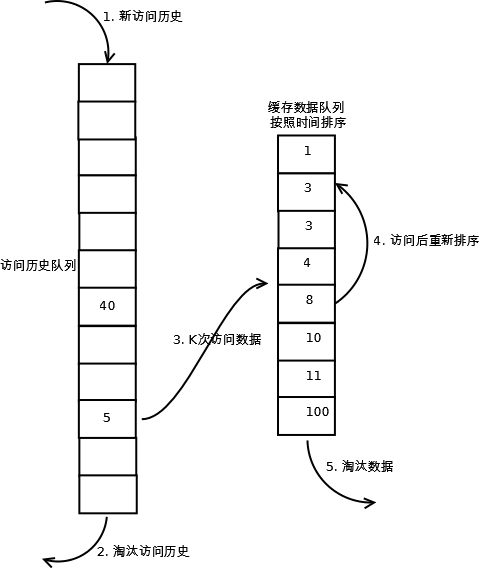
- 数据第一次被访问,加入到访问历史列表;
- 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
- 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 缓存数据队列中被再次访问后,重新排序;
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
K-distance 的概念(LRU-k 是按照 K-distance 排序的):

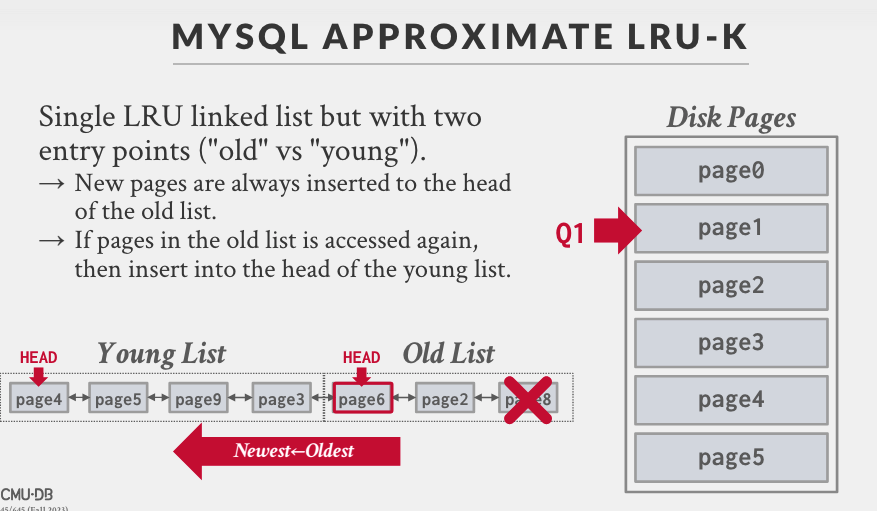
MYSQL 使用了一种类似的算法,第一次访问的时候进入 Old List 链表头,再次访问则从 Old List 转移到 Young List 头部。说它是一种近似是因为它没有真正记录时间戳,只是将其直接放到头部(注意 LRU-k 是会计算 k-distance 的)。
Dirty Pages
Use background writing.