
对应课程
三种数据处理模式
- OLTP: On-Line Transaction Processing
- OLAP: On-Line Analytical Processing
- HTAP: Hybrid Transaction + Analytical Processing
三种存储模型
N-ary Storage Modal(NSM) 行存储
适合 OLTP,一般 Page 大小都是 Hardware Page 的整数倍。
优点:
- 快速增删改查;
- 适合 OLTP;
- 可以基于 index-oriented 实现存储。
缺点:
- 不适用于扫描表的大范围内容;
- 如果是想获取其中一列的值,会有很多随机写,内存 locality 很差;
- 不适合压缩,因为单个页面里面有多种 value domains,重复的值出现的概率低。
Decomposition Storage Model(DSM) 列存储
- 适合 OLAP。
- 一些系统可能会有一个 Buffer Pool,通常是日志结构,缓存行修改,并且定期转换为列存储。
- Oracle 保存以行格式存储的主表,但是同步按列存储的副本。
两种存储方式:
- 定长存储,这样做的好处就是不用额外的表示符确定某个数据(index = offset / value size)。但是对于不定长的数据,则需要通过字典压缩之类的方式,将变长内容映射到固定大小(32 bit)。
- 用额外的列记录
我们在做 OLAP 的时候,往往并不是只看其中一列,我们可能要在多列上获取值并且计算。基于此,我们需要 PAX。
Hybrid Storage Mode(PAX)混合存储
- PAX 即 Partition Attributes Across
Paruqet和Orc格式使用的就是 PAX- 既要获得列存储快速处理的优点,又要获得行存储的优良空间 locality。
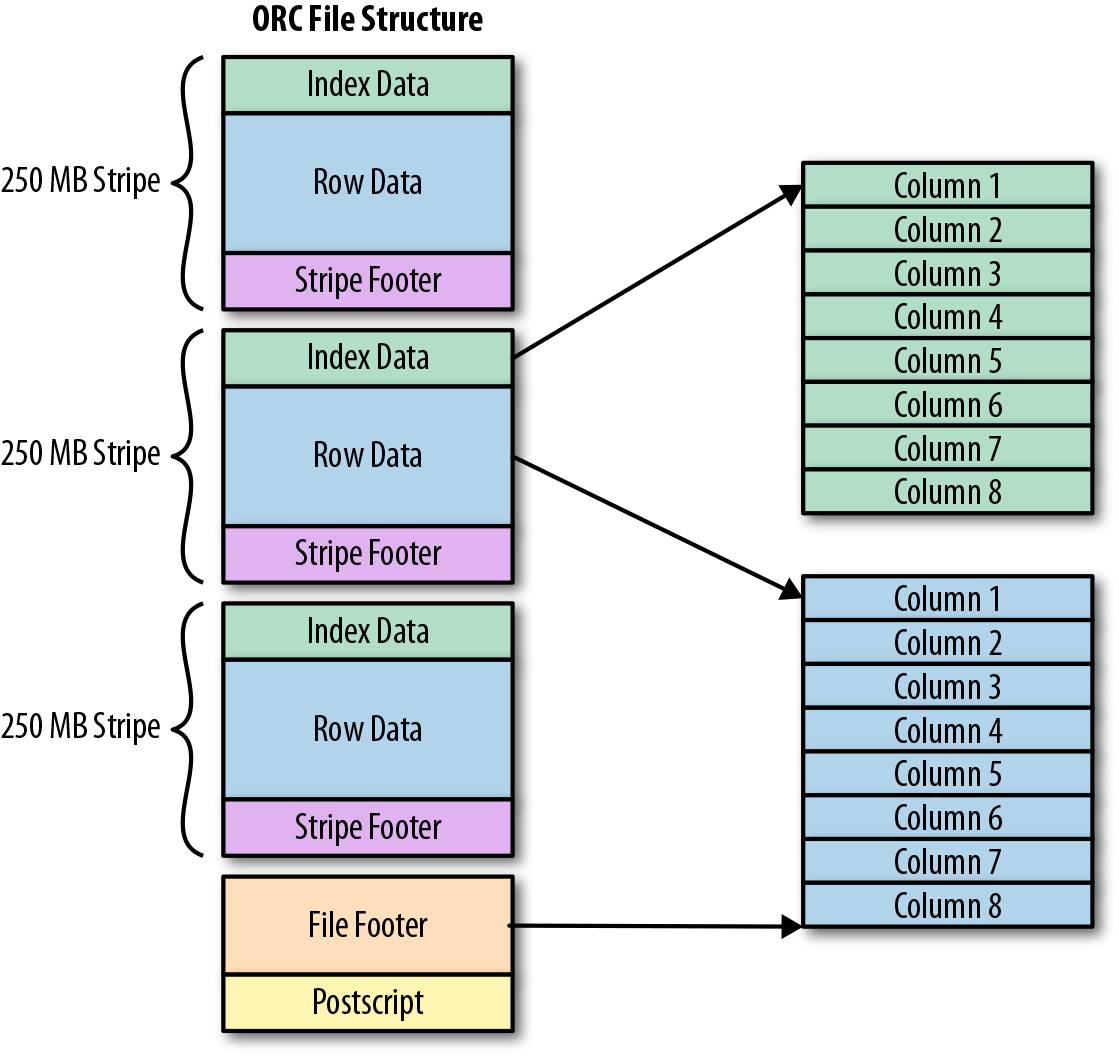
数据库压缩
目标
- 必须产生定长的值
- 解压缩应尽可能被延迟,需要的时候再进行(late materialization)
- 必须是无损压缩
压缩粒度
Block Level(Naive Compression)
- 使用通用压缩算法,Snappy, Zstd 等
- MySQL 使用的是通用的压缩,因为它是行存储,没法针对数据进行很好的压缩。
- 使用通用算法的弊端在于,虽然他们都是基于字典压缩算法的变形,但是由于 MYSQL 无法知道字典数据结构,所以 MYSQL 不得不做整体解压(无法根据字典拿到某个局部值)。

我们真正想要获得的效果应该如下图所示。我们希望能够对某些局部值进行解压缩,而不用解压缩整个页。

我们可以在列式存储中实现这一点。
Column Level
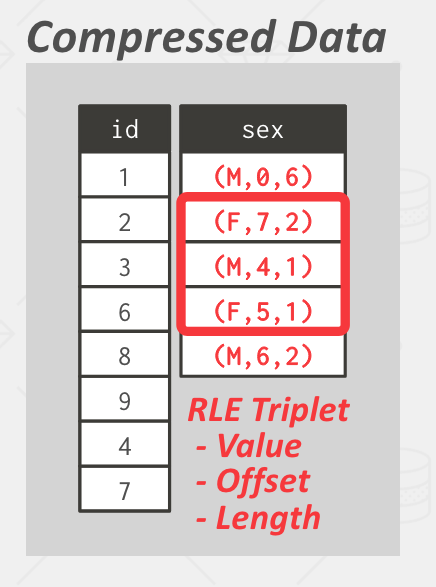
RLE(Run-Length Encoding)
(value, index, number) 三元组,即(数据,索引,数量)。
Bit Packing
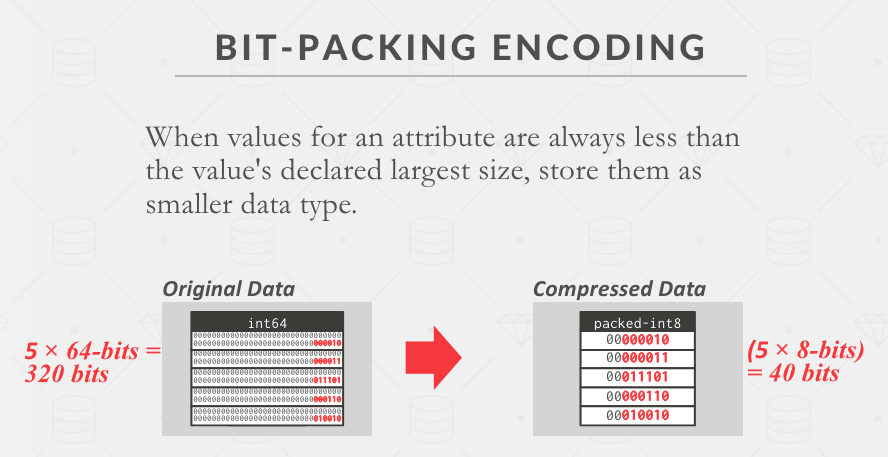
通常数据都不会撑满设定的数值上限,例如 32 字节,我可能最大的数值只有 4 字节不到,那么我们就可以用 4 字节存储一个页中的任一数据(而不是原先的 32 字节)。
Mostly Encoding
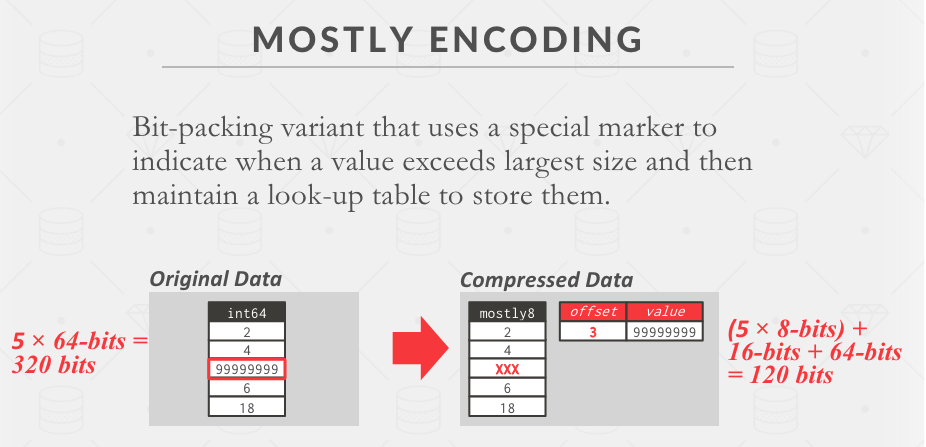
对于 9999… 这么大的数,可以维护一个查询表来存储,其他的数保持 Bit Packing。
Bitmap Encoding
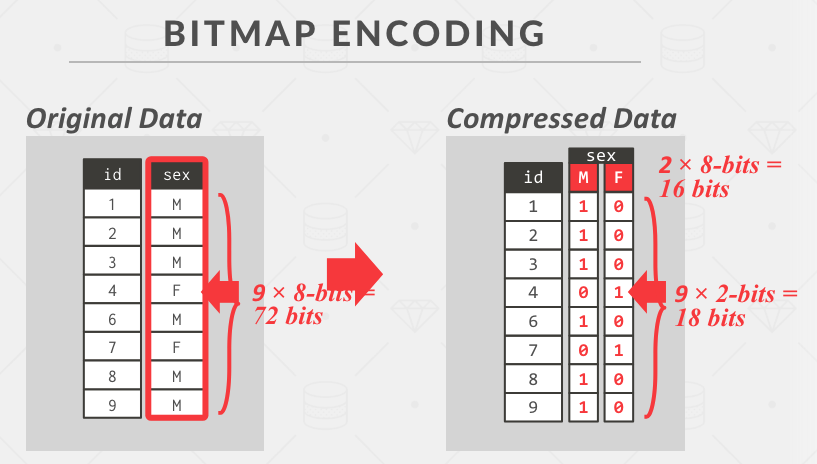
适用于有限值域,这里 M,F 两种值占两个字节 2 * 8 = 16 bits。
Incremental Encoding
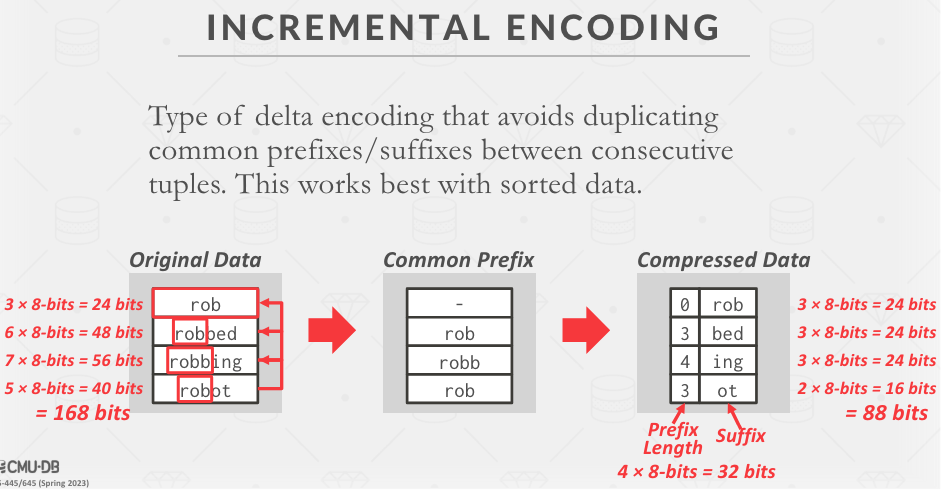
Delta Encoding

利用差值进行压,甚至可以基于 RLE 进一步压缩。
Dictionary Compression
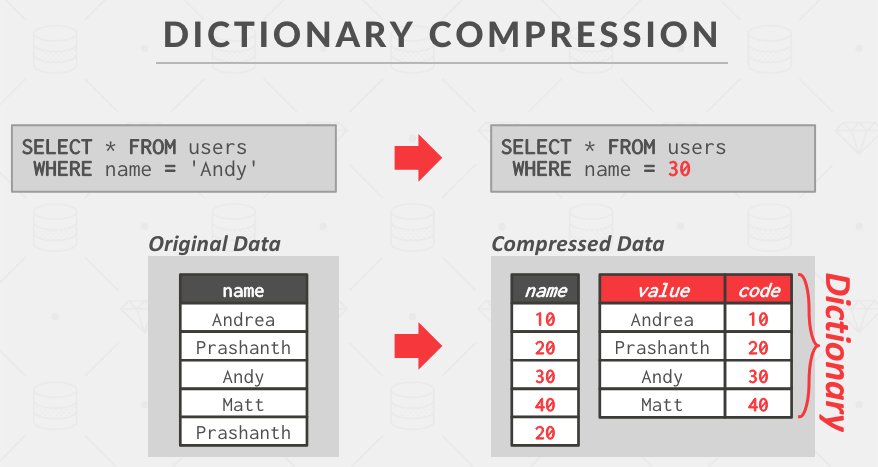
将原始值映射到一个新值,同时维护一个字典记录这种映射关系。
这里查询的时候也需要将查询值进行压缩,不然的话每一行查询都需要将压缩值进行解压,这样就失去了压缩带来的好处。
有时候我们希望对压缩值进行范围查询,所以我们也会希望映射值也能满足顺序。
如果满足字典顺序没有发生变化,那么 DBMS 就可以把 LIKE ‘And%’ 重写成 BETWEEN min AND max 这样的语句(因为满足顺序)。
SELECT name FROM users WHERE name LIKE 'And%';对于 DISTINCT 这样的语句,甚至可以直接在字典上查询(DISTINCT -> 无重复值 -> 字典无重复值)。
SELECT DISTINCT name FROM users WHERE name LIKE 'And%';
