对应课程
聚合操作
- AVG(col)
- MIN(col)
- MAX(col)
- SUM(col)
- …
以上都是 SQL 中的聚合函数。
支持 DICTINCT
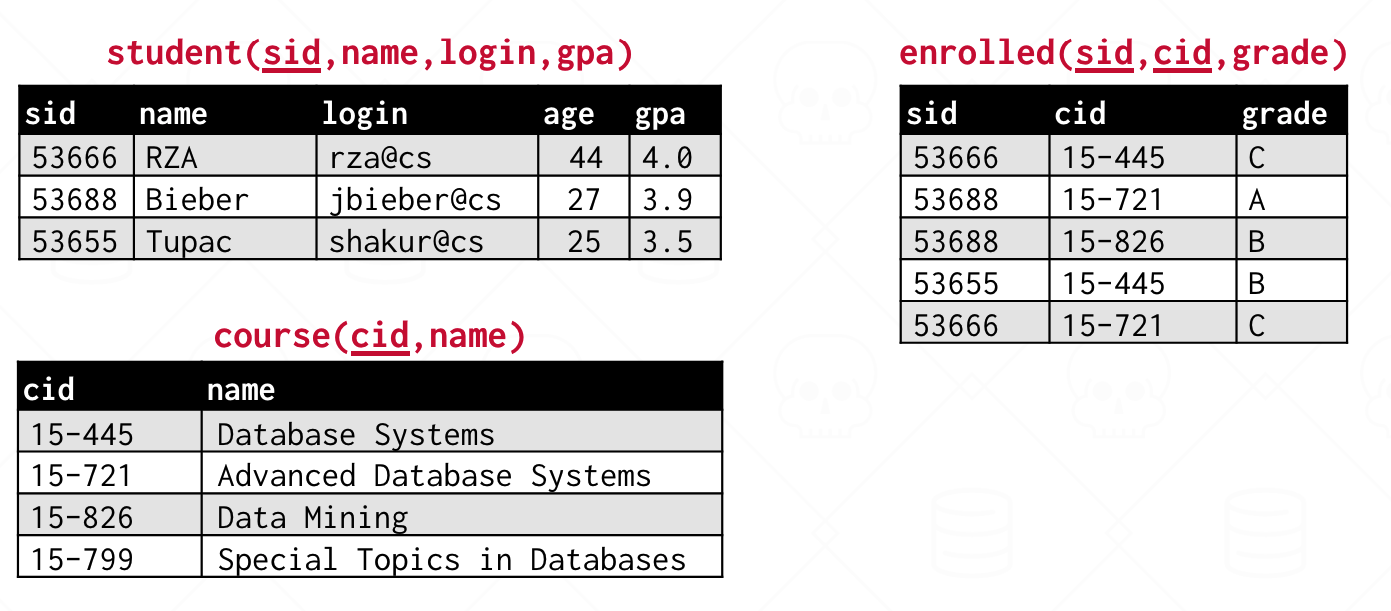
SELECT COUNT(DISTINCT login) FROM student WHERE login LIKE '%@cs'将聚合结果与非聚合的列混合在标准 SQL 下是未定义行为
应该使用
GROUP BYSELECT AVG(s.gpa), e.cid, s.name FROM enrolled AS e, student AS s WHERE e.sid = s.sid GROUP BY e.cid使用
HAVING语句来筛选聚合结果SELECT AVG(s.gpa) AS avg_gpa, e.cid FROM enrolled AS e, student AS s WHERE e.sid = s.sid AND avg_gpa > 3.9 GROUP BY e.cid以上方式是错误的(
AND avg_gpa > 3.9),因为平均值只有在聚合之后才知道。SELECT AVG(s.gpa) AS avg_gpa, e.cid FROM enrolled AS e, student AS s WHERE e.sid = s.sid GROUP BY e.cid HAVING AVG(s.gpa) > 3.9;SQL 是声明式的,AVG 函数不会执行两遍。
字符串

MySQL 默认情况下不区分字符串大小写,使用 CAST 将其转成二进制字符串:
SELECT * FROM student WHERE CAST(name AS BINARY) = 'TupaC';
模糊查询
%类似正则表达式的*_类似正则表达式的.
窗口函数

窗口函数是一种类似聚合函数的函数,但它们不会将数据集分组为单个值,而是在给定窗口范围内对每一行进行计算。
ROW_NUMBER 是窗口函数,OVER 括号里面声明了如何切片,如果为空则代表不切分表。
例如,如果我希望计算每门课第二高成绩的学生:
SELECT * FROM (
SELECT *, RANK() OVER (PARTITION BY cid
ORDER BY grade ASC) AS rank
FROM enrolled) AS ranking
WHERE ranking.rank = 2
嵌套查询

SELECT * FROM student AS s
WHERE s.sid IN (
SELECT sid FROM enrolled where cid = '15-445'
)
LATERAL JOIN
LATERAL JOIN 允许嵌套查询中的表能够引用另一张表的属性
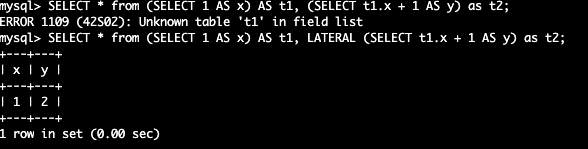
以下的查询会报错,因为 t2 和 t1 是并行执行的,t2 无法知道 t1 的存在。
SELECT * from (SELECT 1 AS x) AS t1, (SELECT t1.x + 1 AS y) as t2;
使用 LATERAL 关键字可以实现这一点:
SELECT * from (SELECT 1 AS x) AS t1, LATERAL (SELECT t1.x + 1 AS y) as t2;
CTE(Common Table Expression)
类似于临时表,或者说是 MYSQL Derived Table(嵌套查询的子查询生成的表叫做派生表) 的增强版。
例子(找到 sid 最大的学生):
WITH cteSource (maxId) AS (
SELECT MAX(sid) FROM enrolled
)
SELECT name FROM student, cteSource
WHERE student.sid = cteSource.maxId
面向磁盘的 DBMS
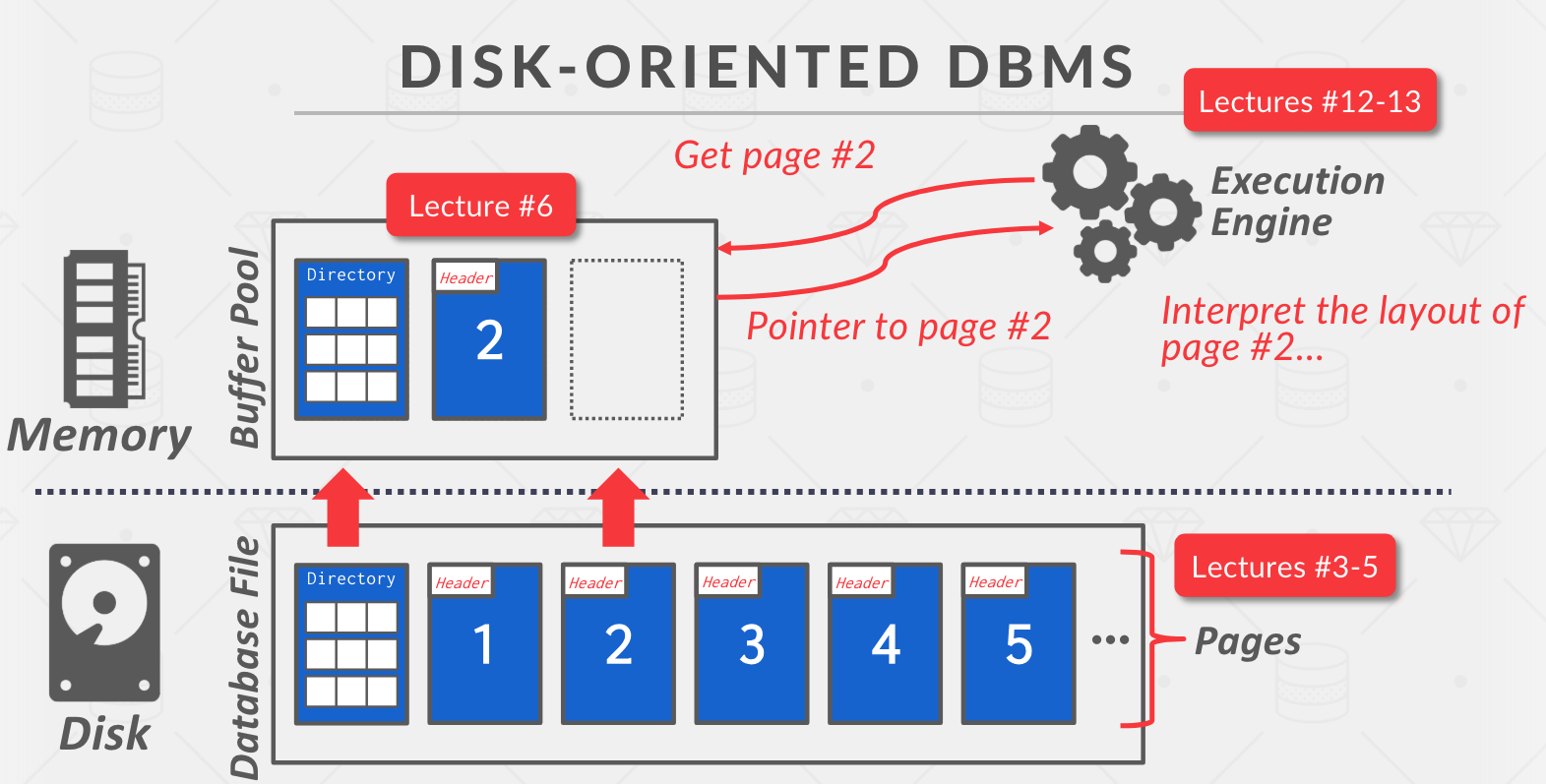
- Buffer Pool 作为中转,缓存数据库页面,页面目录标识数据页在磁盘的位置。
- 获取页面 2 的时候,先加载目录到内存,然后通过操作系统调用加载数据页到内存,返回给执行引擎一个内存地址。
- Buffer Pool 还需要负责写回脏页,保持一致性。
MMAP 的问题
虽然我们可以使用 mmap 调用将文件映射到内存(操作系统会帮我们进行页面换入和换出),但是操作系统执行页面驱逐的逻辑可能和数据库的驱逐逻辑冲突(换出数据库不想被换出的页面)。
- 无法满足事务安全,操作系统可能随时 flash 脏页。假如事务要求将多个页按照一定顺序写入,无法保证 page A 在 page B 写入之后再被写入。
- DBMS 无法知道某个页面在不在内存中,操作系统会触发 page fault 阻塞线程。
- 难以处理错误,任何访问都可能触发一个
SIGBUS中断,DBMS 必须处理它,即使正在执行一些 critical section。 - 与操作系统产生数据竞争。
Storage Manager
- 负责维护数据库文件
- 调度读写以获取更好的时空 locality。
- 以页的形式组织数据库文件
- 记录元数据(可用页面)
Page
固定大小的数据块
数据 + 元数据、日志
Oracle 中 Page 是 Self-contained(包含了用于理解这个页的元数据,比如所属 Table 的信息,这种冗余可以避免数据库文件损坏导致无法读取数据)。
每个页都有一个唯一标识符(由此映射到物理内存位置)。
Hardware Page(4KB)是能够保证原子性写入的数据块最大大小。数据库页默认大小通常大于 4KB(非原子性)。

Heap File
页的无序集合,每个数据元祖随机存储(关系型数据库并不要求按照顺序排列)。对于单个文件而言,找到对应的页很容易,但是对于多个文件而言则比较棘手,需要存储额外的元数据记录哪一个页存在哪一个文件里面,也就是 Page Directory。Page Directory 需要和数据页保持同步,同时需要维护和记录空闲页的数量和位置。

- 对 Page Directory 的更新需要立即写入磁盘。
- 像 BLOB 这种字段可能是分另一个文件存储。
Page Header
存储诸如页大小,校验和之类的元数据。
Tuple-Oriented Storage
File -> Page -> Tuple
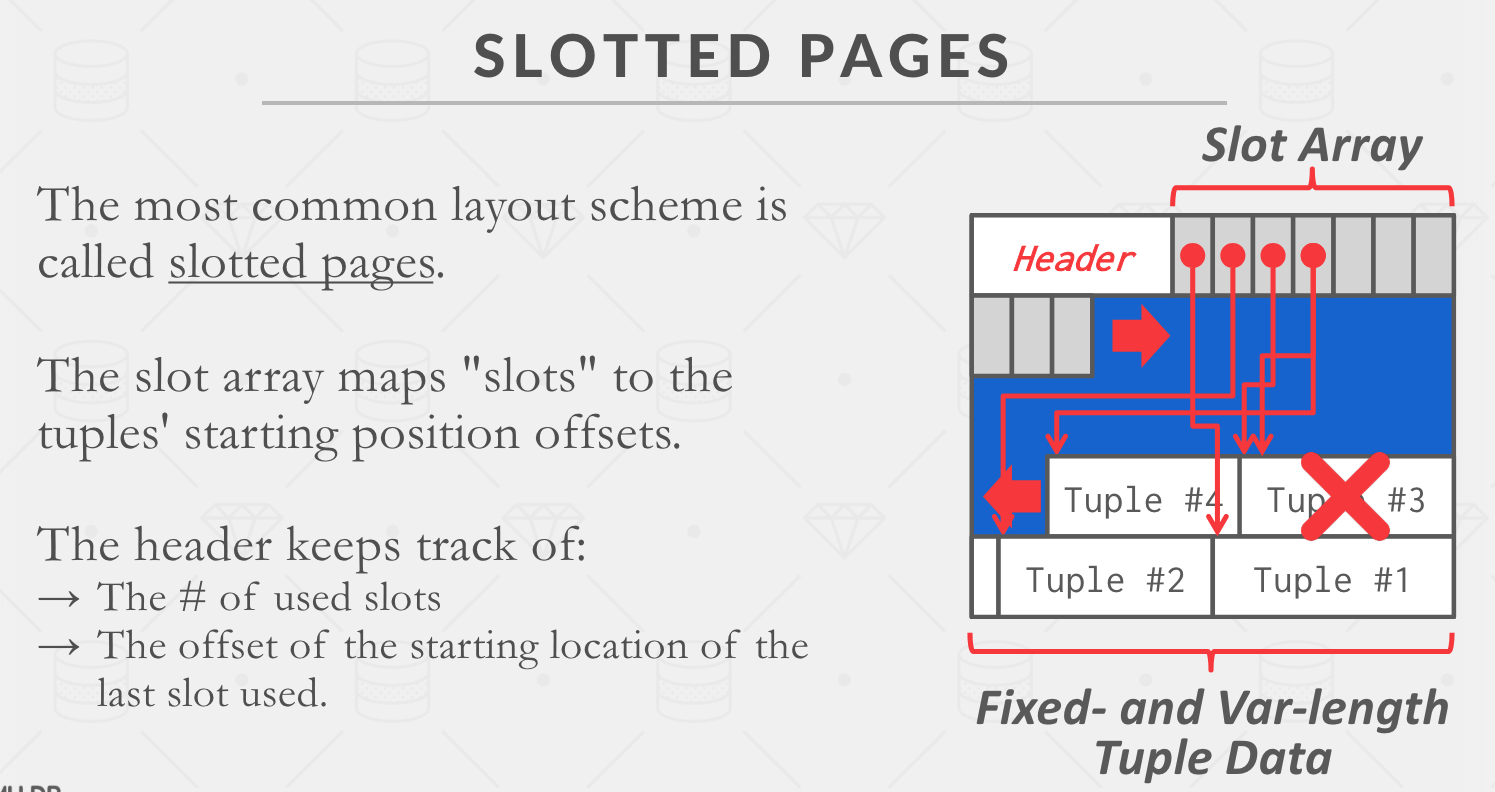
- 使用 Slotted Pages,Slot Array 从头部往尾部增长,Tuple 从尾部往头部增长。
- 使用 Record ID 唯一标识一个 Page(Postgresql 中的
ctid)。
存在的问题:
- 一个 page 中可能有大量未被使用的空间(内存碎片);
- 更新一个 tuple 需要读写整个 page;
- 随机磁盘读写,极端情况是修改 N 个 tuple,每个都属于不同的 page;
- 由于需要写回更新,在一些云存储系统可能不支持这么做,例如
HDFS。
Log-Structured Storage

- 追加对 tuple 的 PUT/DELETE 操作
- 定期合并 page(compaction)

存在的问题:
- 写放大:Compaction 非常昂贵,从磁盘读回内存再写回磁盘。
- 读放大
NULL
- 通过一个 bitmap 标识属性是否为空,这通常不仅仅占一个 bit,因为还要解决内存问题(填充多个 0)。
- 标记为非 NULL 就不需要存 bitmap。
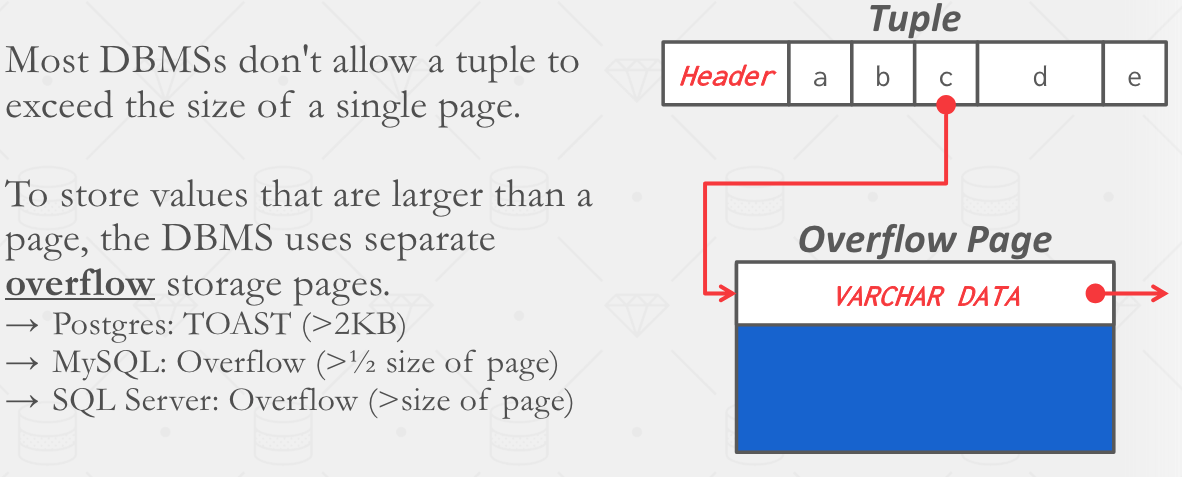
Large Values & External Value Storage