
正文
该笔记将记录在 Ubuntu-20.04 上安装并使用 Spark 的历程。
环境
- Ubuntu 20.04
- Spring Boot 3.2.3
- Spark 3.2.0
- JDK 17
安装参考:在 Ubuntu 20.04 上安装 Apache Spark 教程。
启动流程
启动
master:start-master.sh这个指令会在当前主机启动一个 master 节点,可以在
localhost:8080访问到控制面板。
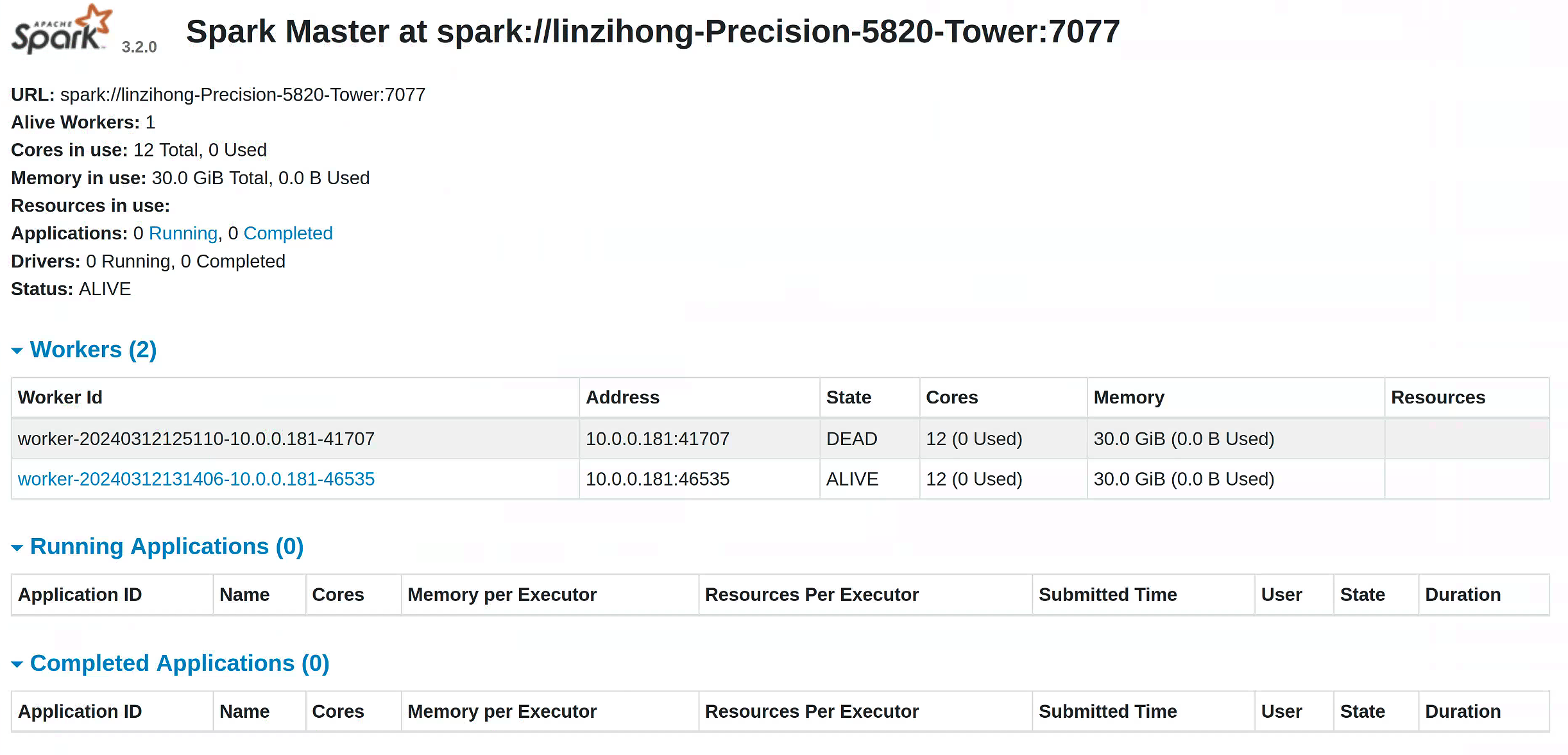
启动
worker:复制命令行中生成的
master节点的 URL,启动worker:
start-worker.sh spark://xxx启动成功后长这样:
配置 Java Spark 环境
Spring Boot + Spark:
遇到的问题:
- Running unit tests with Spark 3.3.0 on Java 17 fails with IllegalAccessError: class StorageUtils cannot access class sun.nio.ch.DirectBuffer
- cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not
- java.lang.ClassNotFoundException: org.slf4j.impl.StaticLoggerBinder
- java.lang.ClassNotFoundException: java.servlet.Servlet
- Java Spark connection fails UnavailableException: Servlet class org.glassfish.jersey.servlet.ServletContainer is not a javax.servlet.Servlet
这一套 pom.xml 是可以用的:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.reins</groupId>
<artifactId>spark</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spark</name>
<description>spark</description>
<properties>
<java.version>17</java.version>
<jakarta-servlet.version>4.0.3</jakarta-servlet.version>
<jersey.version>2.36</jersey.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.43</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.github.shyiko</groupId>
<artifactId>mysql-binlog-connector-java</artifactId>
<version>0.21.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>3.0.9</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
注意:在我的环境中,worker 占用了 8081 端口,而我的 Spring 服务启动在 8081 端口,所以产生问题。按照上面的链接能够解决剩余的版本冲突问题。
- Spark异常:org/codehaus/janino/InternalCompilerException
不能用太高版本的,3.1.2 也不行。
简单的例子
经典 word count:
JavaRDD<String> file = session.read().textFile(filePath).cache().toJavaRDD(); JavaRDD<String> words = file.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(s.split(" ")).iterator()); JavaPairRDD<String, Integer> wordToCountMap = words.mapToPair((PairFunction<String, String, Integer>) s -> new Tuple2<>(s, 1)); JavaPairRDD<String, Integer> wordCounts = wordToCountMap.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum); wordCounts.saveAsTextFile("./word_count");
参考:
生成 parquet:
SparkSession session = sparkService.getSparkSession(); Properties properties = new Properties(); properties.setProperty("user", "root"); properties.setProperty("password", "123456"); Dataset<Row> dataset = session.read().jdbc("jdbc:mysql://localhost:3306/spark", "person", properties); // 输出表格 dataset.show(); dataset.coalesce(1).write().mode(SaveMode.Overwrite).option("header", true).parquet("./test.parquet");
Pandas 也支持生成 parquet:pandas.DataFrame.to_parquet。
Spark 中的三种数据结构
Spark RDD
RDD是一种弹性分布式数据集,是一种只读分区数据。它是Spark的基础数据结构,具有内存计算能力、数据容错性以及数据不可修改特性。Spark Dataframe
Dataframe也是一种不可修改的分布式数据集合,它可以按列查询数据,类似于关系数据库里面的表结构。可以对数据指定数据模式(schema)。Spark Dataset
Dataset是DataFrame的扩展,它提供了类型安全,面向对象的编程接口。也就是说DataFrame是Dataset的一种特殊形式。
参考: