ChatGPT 告诉我们 Trajectory 和 Episode 的区别

步骤
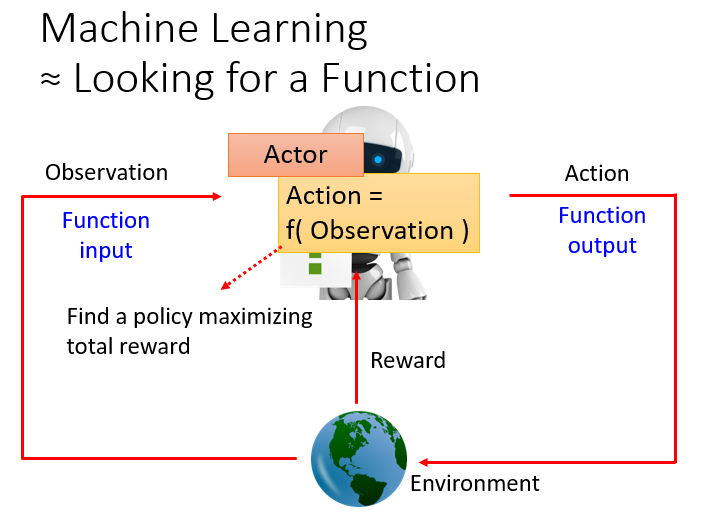
强化学习的步骤和基本的机器学习的步骤是类似的:
第一步:找一个具有未知参数的函数:
在强化学习中对应于
Actor的Policy Network,它通过从Environment获取Observation,并基于此预测要执行什么Action。
如果这里的Action是stochastic的,那么就会得到一个Action的概率分布,类似于分类问题.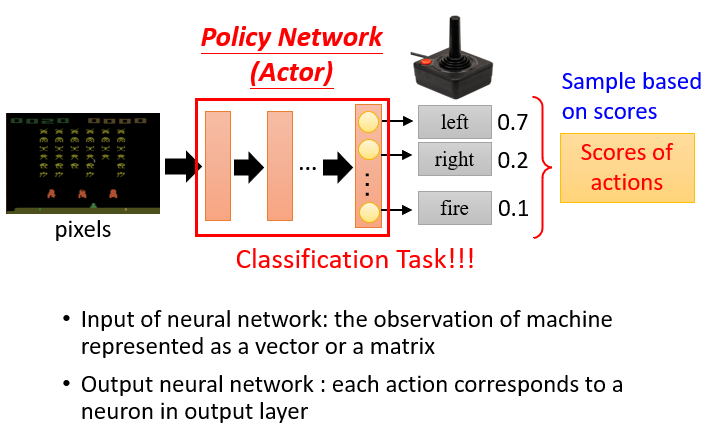
第二步:定义 “loss”:
我们要使得获取的总体奖励的期望值最大。
Total reward=Return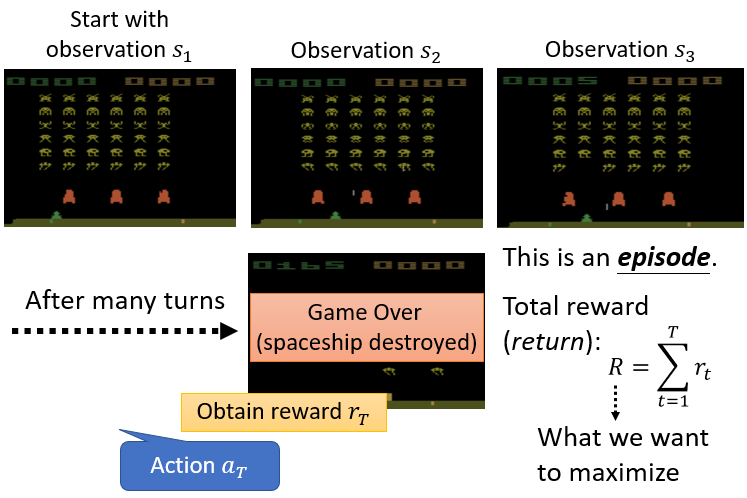
第三步:如何进行优化:
需要定义一个结束条件,然后让模型经历一个
Trajectory,要使得这个Trajectory获得的Reward最大。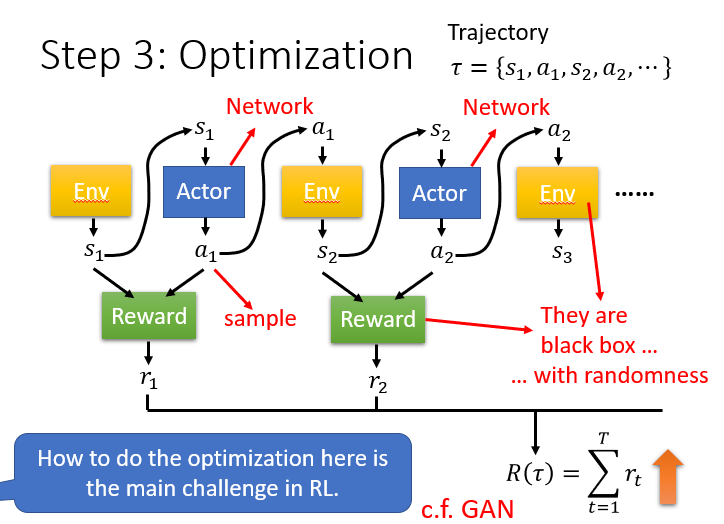
Actor与Critic和GAN有异曲同工之妙。Actor对应于Generator,生成带有随机性的决策;Critic对应于Discriminator,判定决策的分数,
并为Actor修改策略提供依据和指正。但是不同点在于,GAN中的Discriminator是一个已知的可训练的 model,而强化学习中的Environment和Reward更像是一个黑盒子,
它们根本不是模型,无法用一般的梯度下降法来解决。
How to control actor
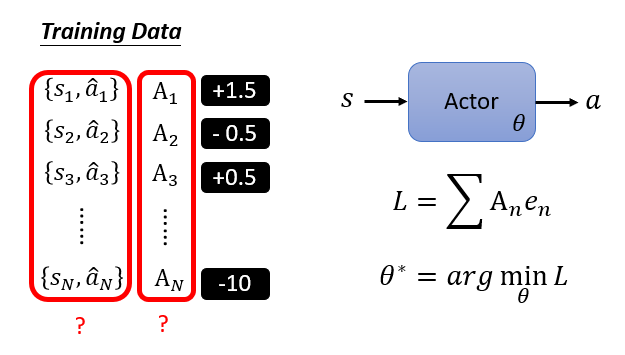
其中
Version 0
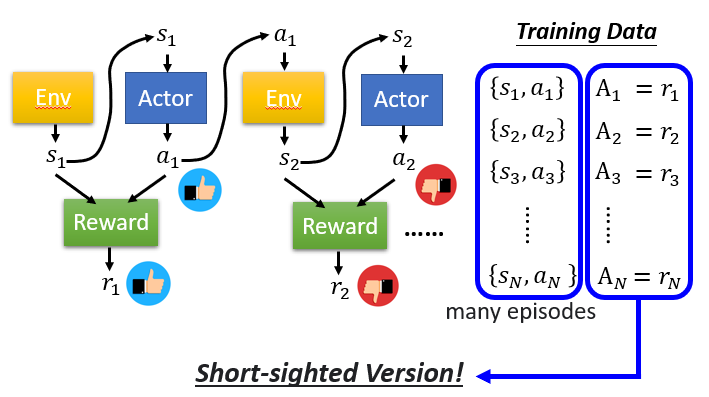
缺点:如果只用一个动作获得的奖励(而不看后续获得的奖励的话),那么
actor就会偏向于只追求短期利益,
只追求会获得奖励的动作。这显然是错误的,本质上就是一种贪心策略。Version 1
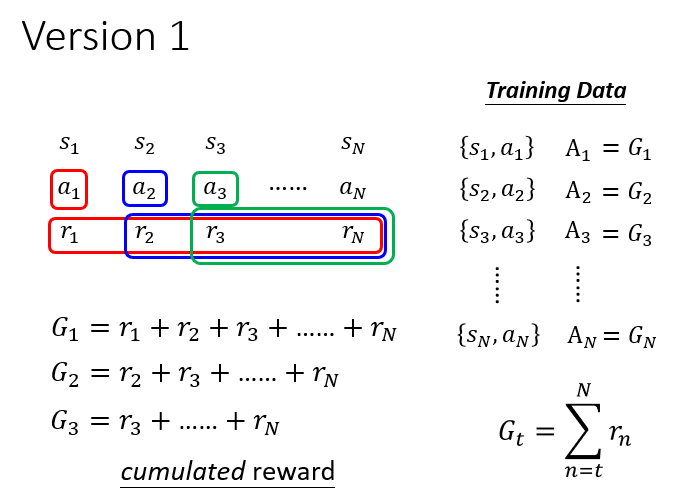
改进之后会考虑后续的奖励了,但是在很久之后获得的奖励
真的可以归功于动作 吗?显然不能!
我们希望奖励前面有个系数,且这个系数是衰减的,越遥远的奖励和当前执行动作的相关性往往越弱。Version 2

引入折扣因子
解决上述问题。 Version 3
奖励是相对的,有些环境只会产生正的反馈,那么如果不对奖励进行修正,那么一些低奖励的动作也会被鼓励。
因此,可以对奖励减去基准,以对奖励进行标准化。 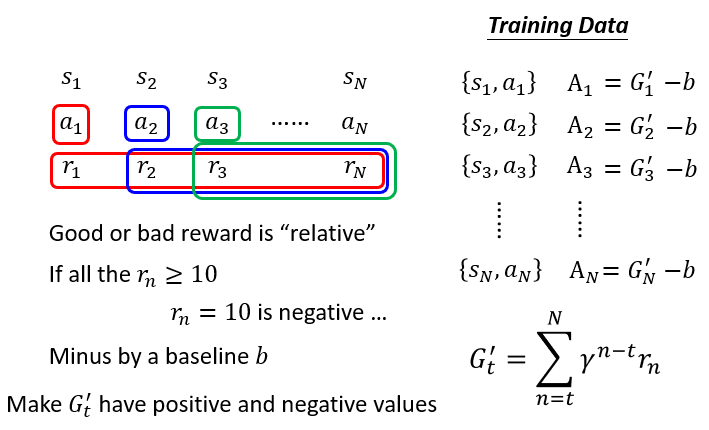
Version 3.5
如何更好地确定系数
?使用下面讲到的 Critic的Value function: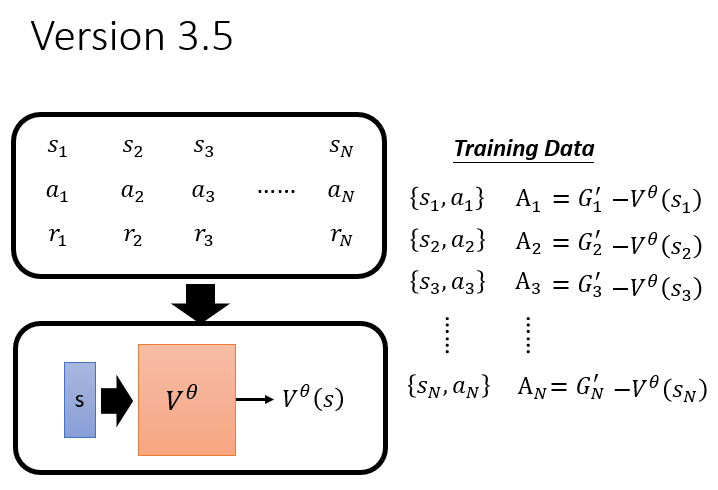
是一个期望值,也就是一个均值(相当于你随机做一串动作获得的奖励差不多就是这个值),作为被减去的 `baseline`。 则是 `actor` 获取的实际收益。如果说这个收益大于均值,我们就认为这个动作是好的,是值得鼓励的。 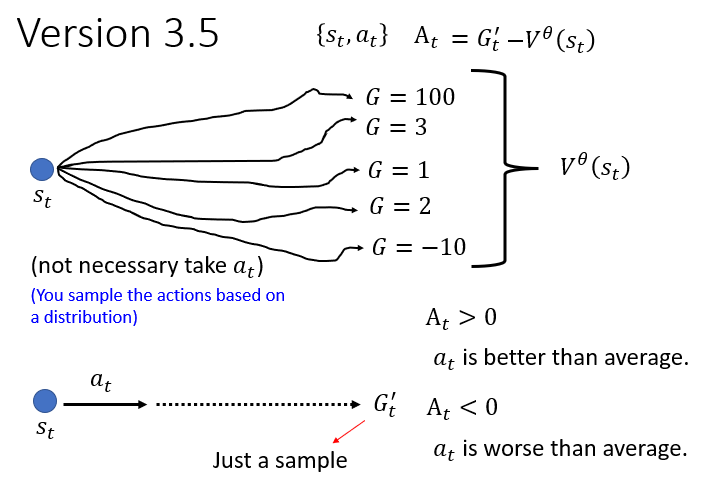
Version 4
是多条路径取平均的结果(因为你在训练 `Critic` 网络并且让其趋向于期望值), 而
则是某一个 sample的结果,假如说这个sample碰巧特别好或者碰巧特别坏,
那么这样计算出来的差值真的能用来评估这个在状态下的动作 的好坏吗? 举个例子,假如说极端一点,
其实是一个极好的决策,但是后面的决策都做的烂的惨不忍睹,导致 ,这会导致 。
这样就说明我们非常不鼓励actor去做,这不就事与愿违了吗? 所以正确的做法应该是用平均减去平均,以评估
这一动作的优劣,这也就是大名鼎鼎的 A2C(Advantage Actor-Critic):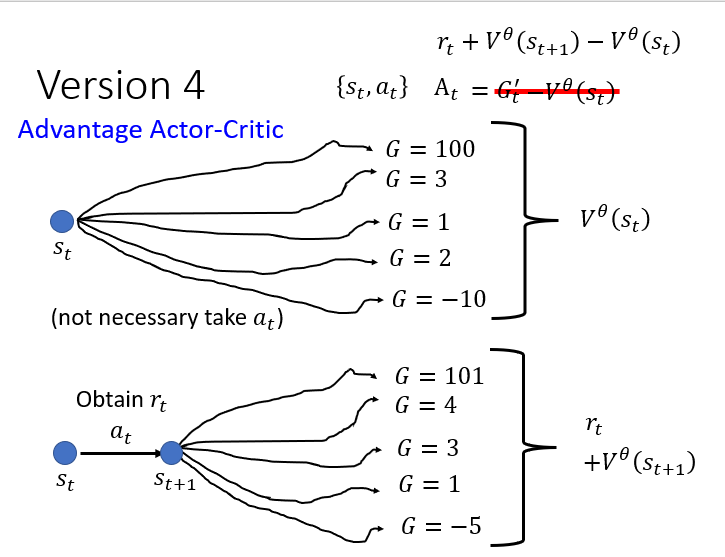
注意到,我们上面说了
会趋向于累计奖励的期望值(乘上折扣因子),也就是说: 故而有:
这里 ppt 上因为之前假设
,所以上面省略了 这一因子。
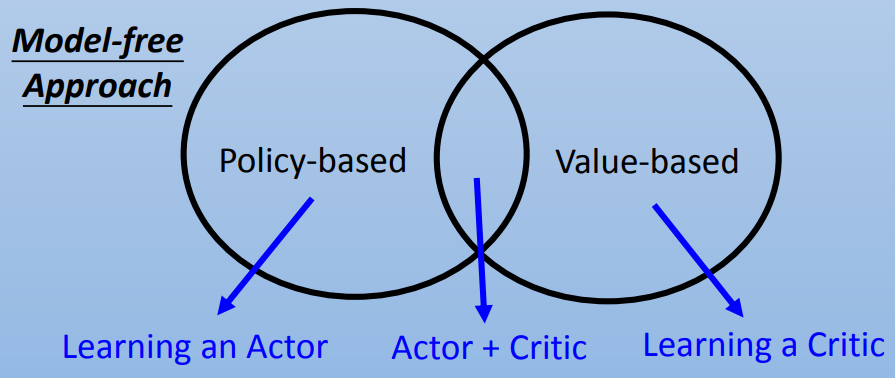
Policy-based & Value-based
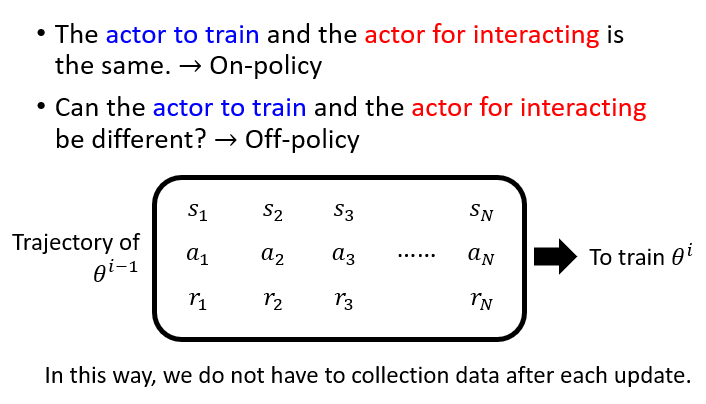
On-policy vs Off-policy
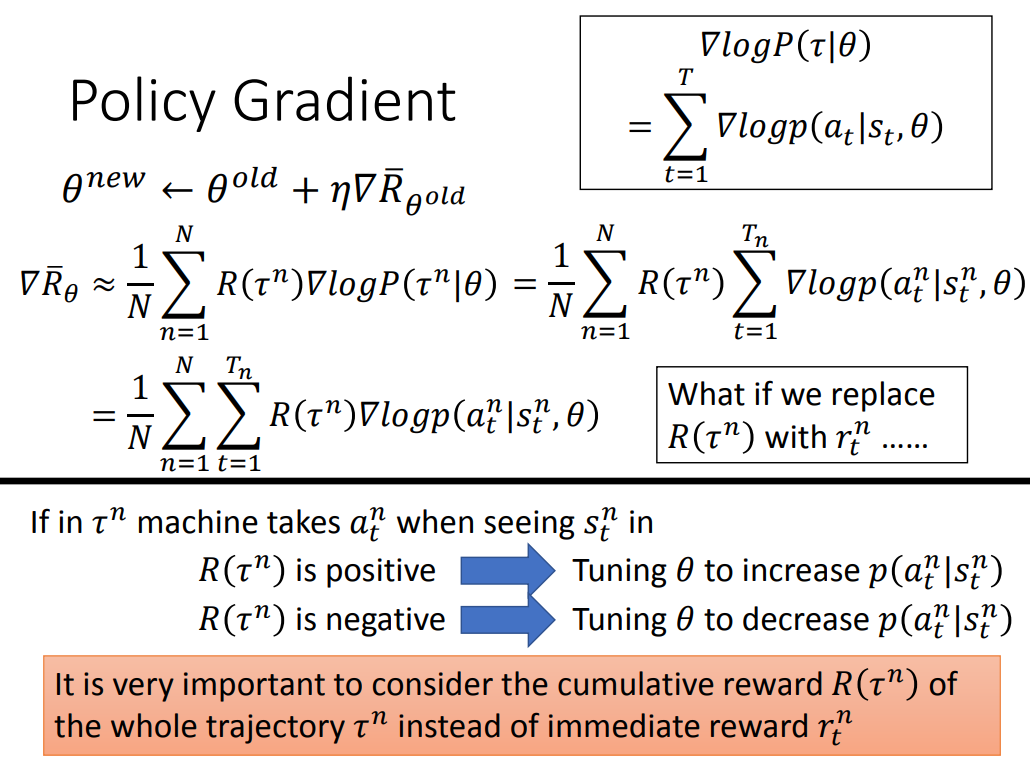
Policy Gradient
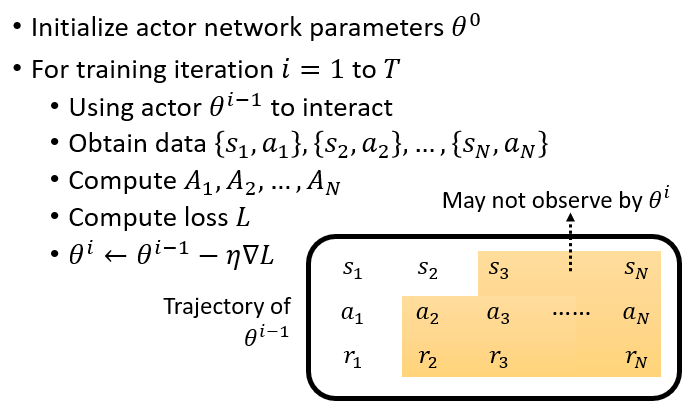

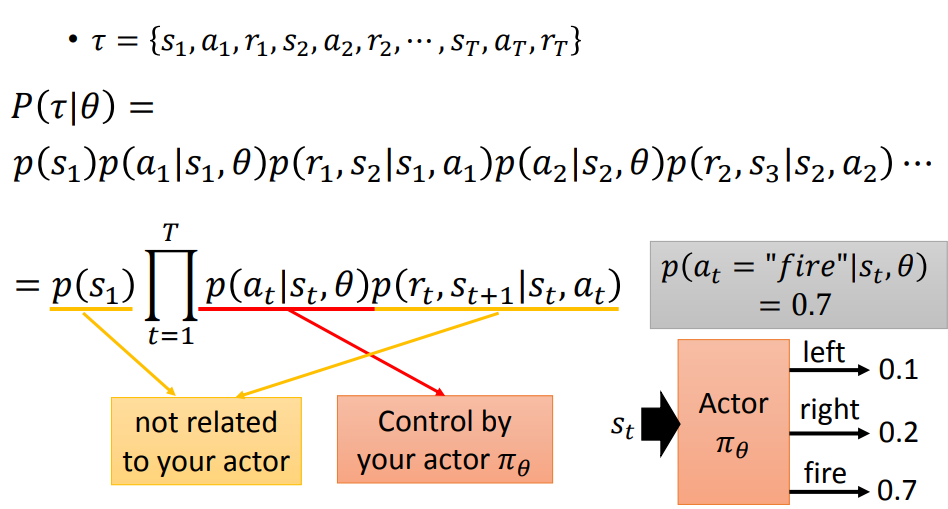

接下来就可以用 Gradient Discent 来解决这一问题:

这里认为
由右边的导数公式就能算出最后的结果。
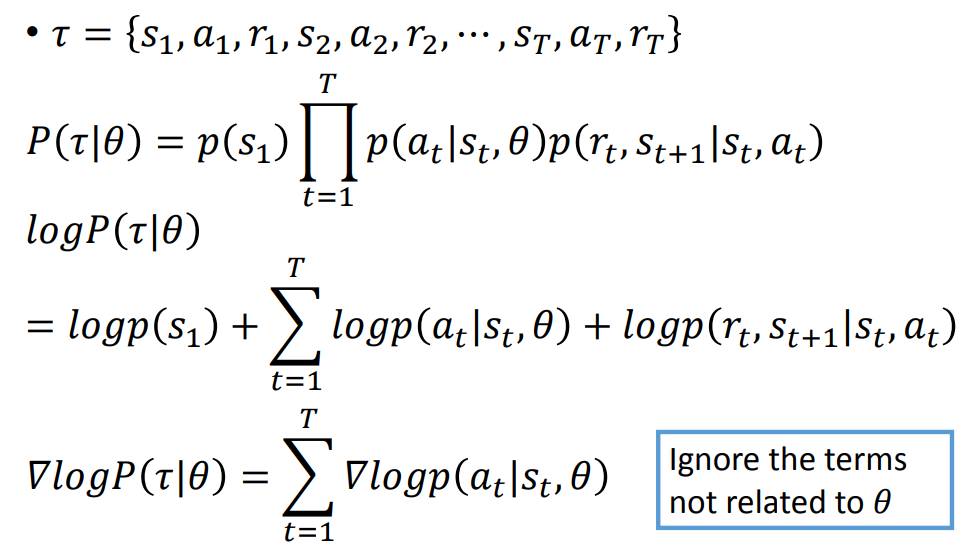
Actor-Critic
Critic
Critic 会有一个 Value function actor 看到状态
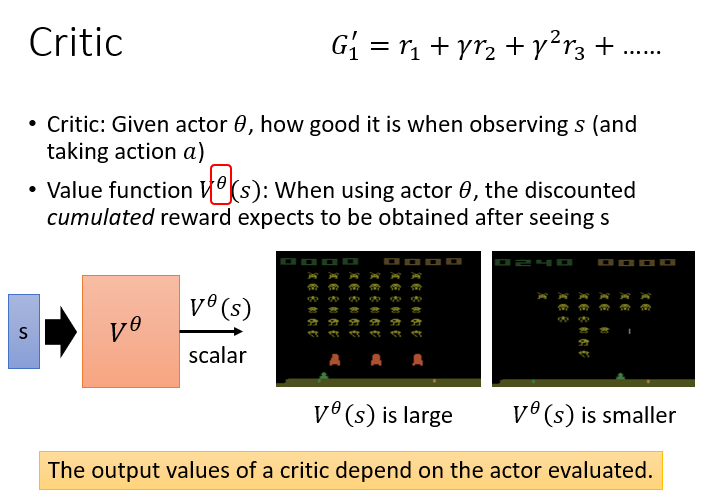
如何训练 Value function
蒙特卡罗方法
让
actor与环境交互若干次。每次都会获取奖励,我们期望 的值和 越接近越好,可以用 MSE作为损失函数。比如下面的例子,我们就希望
与 越接近越好。 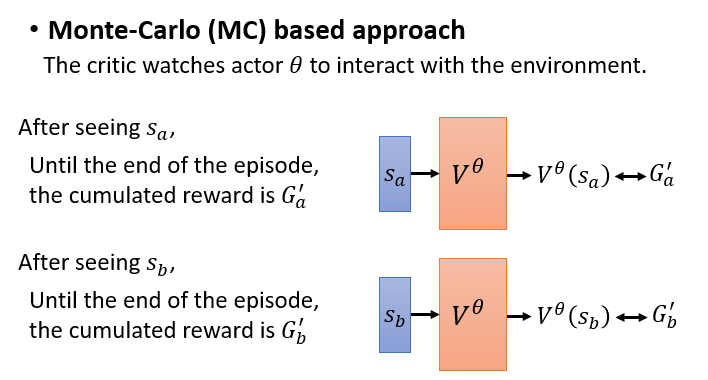
Temporal-Difference(简称 TD)
与蒙特卡罗方法不同,
TD是每一步都进行参数更新。由:
, 可知:
所以此时我们只要让
和 尽可能接近就行。因为在 时刻获得的奖励 是已知的。 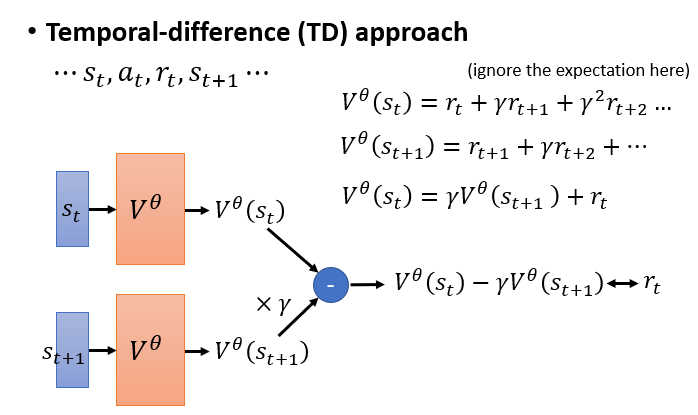
蒙特卡罗方法和 TD 可能会计算出不同的

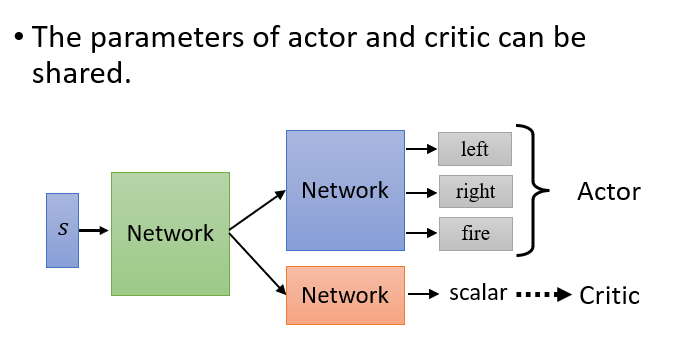
整体训练技巧
Actor 网络和 Critic 网络可以共享。
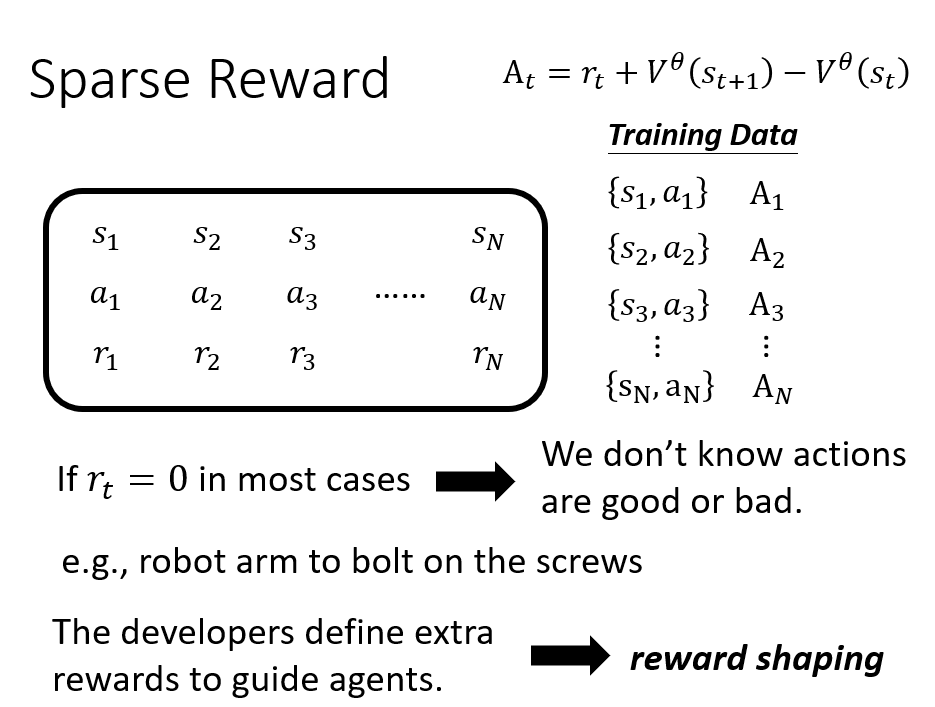
Reward Shaping
在有些环境中,大多数 action 都无法获得或者无法获得较多的 reward,而只有极少数 action 或者只有在最后才能获得较多的 reward(比如围棋)。
我们需要设计额外的 reward 帮助 agent 学习,也就是 reward shaping。
为 agent 赋予 curiosity,在探索环境中获取 reward,但是必须要避免一直读无意义的新内容以获取 reward。
No reward: Learning from demonstration
在有些情况下,我们甚至连 reward 都没有,或者说我们难以设计一个好的 reward。
这时候,我们可以用一组 export 的 demonstration 来为 agent 提供“动作指导”。
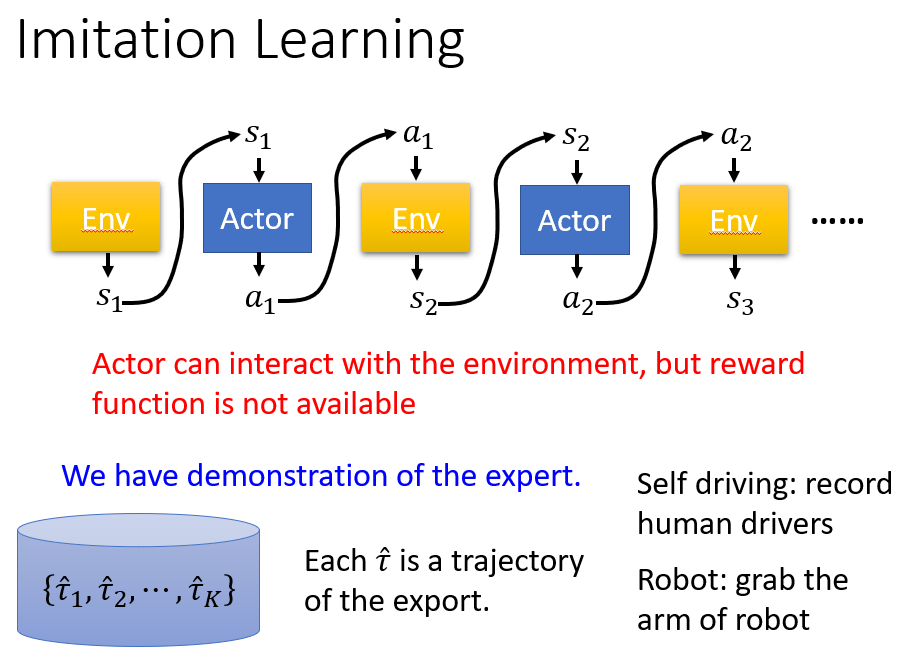
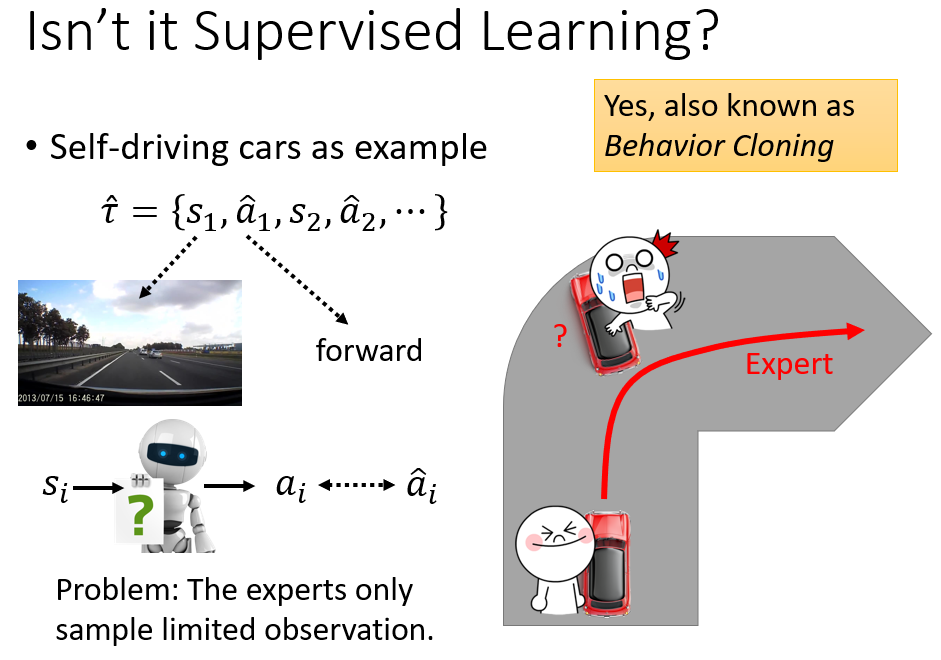
这种方式有点类似于监督学习,但是我们不能只用监督学习的方式来训练 agent。使用监督学习,实际上就是让 agent 学会模仿 export 的动作,本质上是一种 cloning 的行为。
但是,我们往往无法知道 export 的 demonstration 里面哪些是不该学习的“个性化”的 action。而且,如果只学习 export 的 demonstration,那么 agent 就会无法学习到一些突发情况的解决方式,
因为 export 实在太厉害了,往往都是顺利地解决问题。
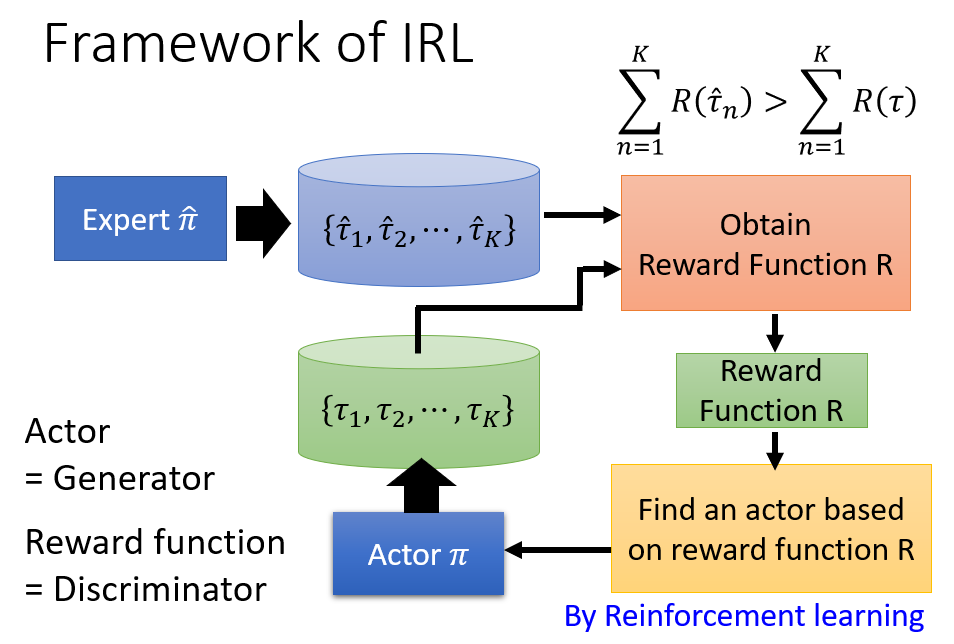
Inverse Reinforcement Learning
我们可以通过 export 的 demonstration 来学习一个 Reward Function,然后再利用这个 Reward Function 进行普通的强化学习。
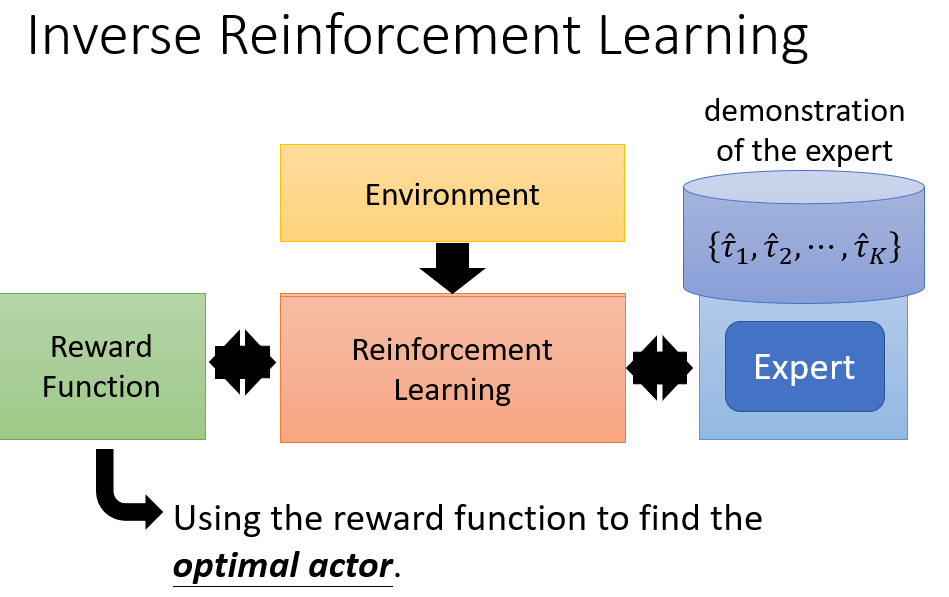
我们需要定义一个 reward function,对于老师的行为和学生的行为都会去评估他们的奖励,我们希望老师的奖励应该要大于学生(学生的奖励 - 老师的奖励作为损失),并且对于学生而言,
它的目标就是学习获得最大的奖励(基于新的 reward function)。

整体的框架和思想其实和 GAN 有异曲同工之妙。