
自注意力机制的矩阵运算:
q即query,k即key,v即value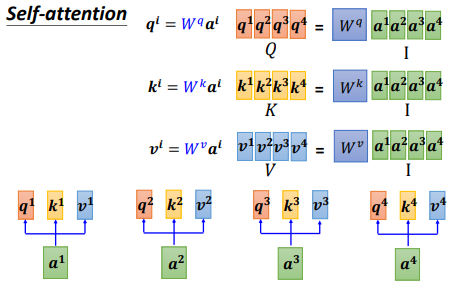
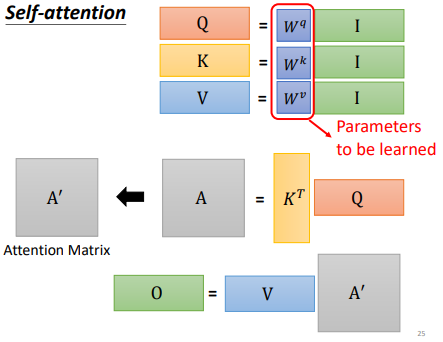
α即为注意力分数,经过softmax进行归一化得到α',并与v相乘得到最终的b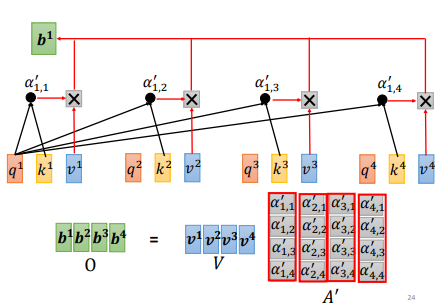
为什么我们需要多头注意力机制(
Multi-head Self-attention)?Self-attention实际上就是去找和q相关的k,但是相关性是一个比较复杂的东西,我们往往需要多个维度对相关性进行描述,
即使用多个q负责不同的相关性。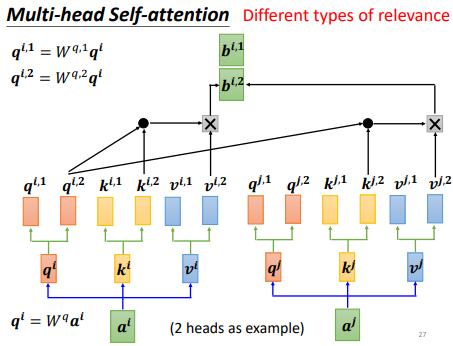
将多个头获取的
bi进行 concat:
有什么不足?缺少位置信息:
解决方案:
positional vector,每一个位置都对应一个不同的位置向量ei,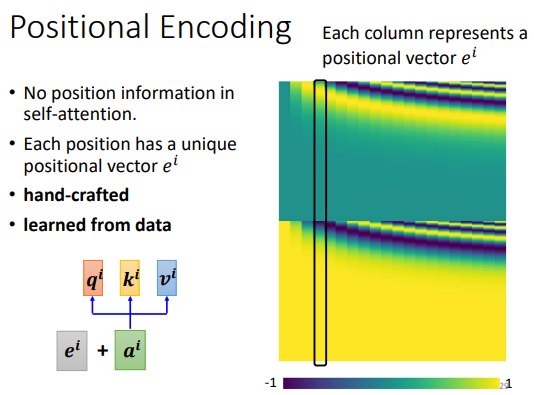
我们真的需要读一整句话吗?
对于像语音识别这样的序列而言,我们会把每 10ms 的语音数据作为一个向量,那么一句话就会对应相当可观的序列长度
L。而我们产生的注意力矩阵的规模和L的二次成正比,
如果L非常大的话,注意力矩阵也会相当大。所以我们实际上不会读一整个句子,而是使用所谓Truncated Self-attention去读一个窗口(其大小可以自行指定)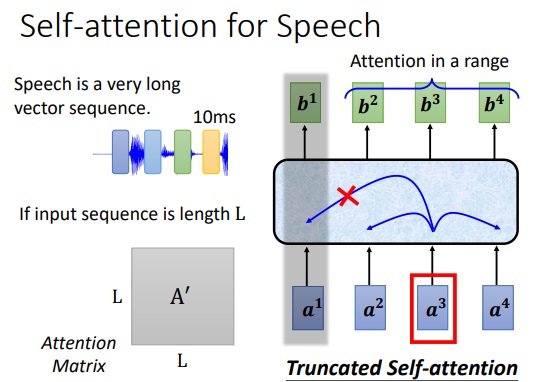
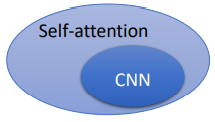
Self-attentionvsCNN:图片亦可作为
set of vector,所以Self-attention亦可用于图像领域。CNN的卷积核代表了一片感受野,其大小是受限的,而Self-attention则关注了整张图片的信息。CNN is simplified self-attention(self-attention that only attends in a receptive field).
或者你也可以说:
Self-attention is the complex version of CNN(CNN with learnable receptive field).
Self-attentionvsRNN:RNN只能获取左边已输入的序列的信息吗?不,可以用双向RNN,即Bidirectional RNNSelf-attention可以并行处理(矩阵运算,GPU 优化),并且可以轻易获取非常远的上下文信息。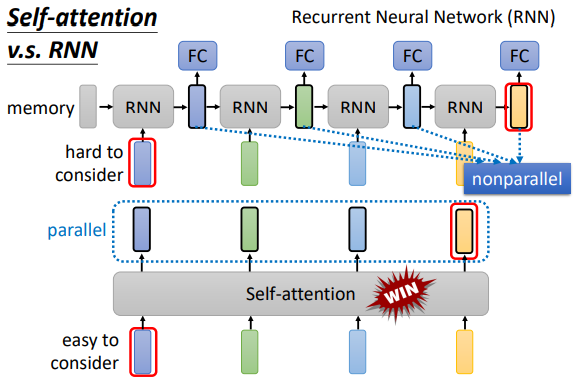
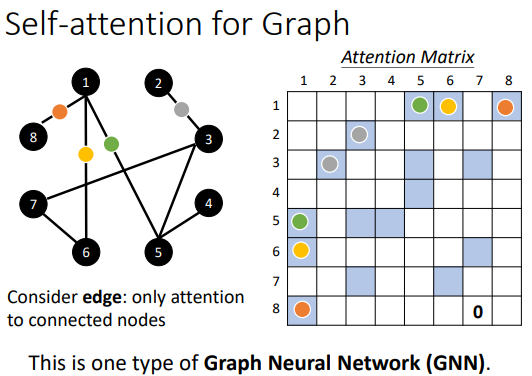
在图中使用自注意力机制:
Self Attention 笔记
2022/11/20
AI