C++ 知识查漏补缺
使用 std::tie 读取 std::pair
std::pair<int, double> p{1, 2.0};
int i;
double d;
std::tie(i, d) = p;
std::span
std::span 就是一个连续对象存储的观察者。类似std::string_view 是 std::string 的观察者。
int printSize(std::span<int> s) { std::cout << s.size() << std::endl; }
int main() {
std::vector<int> v{1, 2, 3};
int a[10];
std::array<int, 30> arr;
printSize(v); // 3
printSize(a); // 10
printSize(arr); // 30
}
std::vector 释放内存
std::vector::clear 并不会释放 capacity,需要使用 std::vector::shrink_to_fit 或:
std::vector<int> v{1, 2, 3};
std::vector<int>().swap(v);
std::cout << v.capacity() << std::endl; // 0
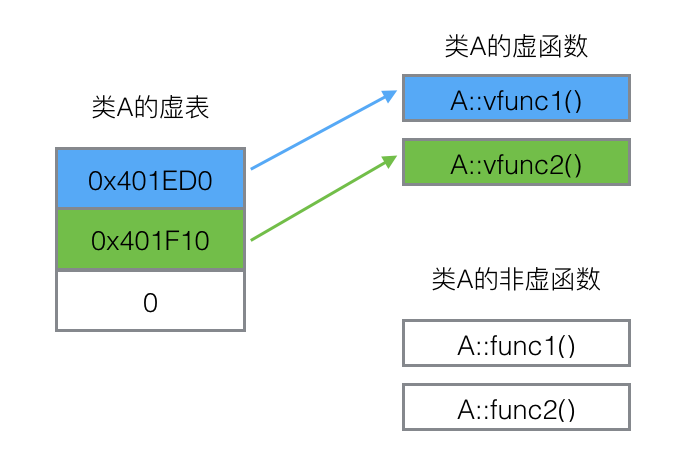
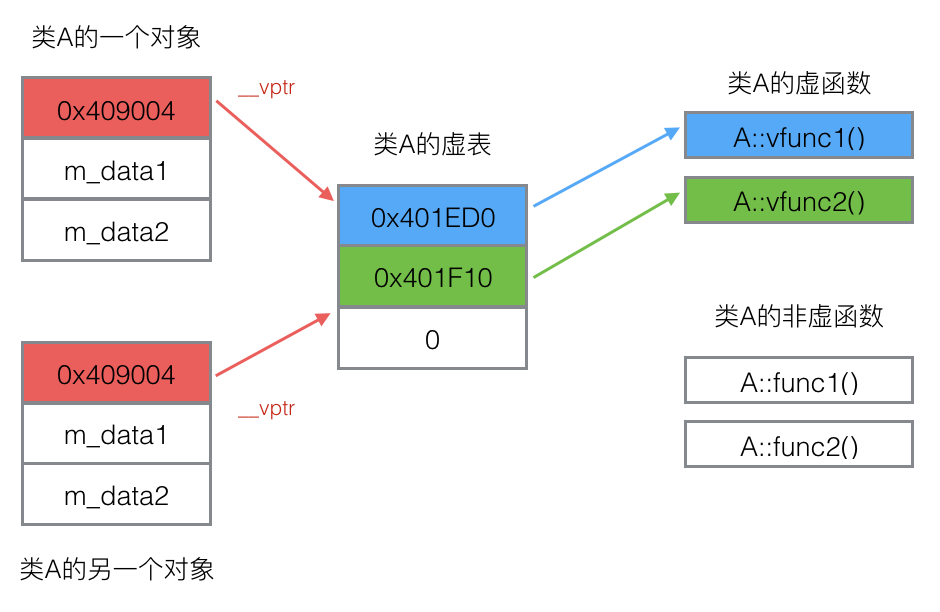
虚函数表占的空间
class A {
public:
virtual void vfunc1();
virtual void vfunc2();
void func1();
void func2();
private:
int m_data1, m_data2;
};
手写一个 std::function
#include <iostream>
template <typename R, typename... Args> struct ICallable {
virtual R invoke(Args &&...args) = 0;
virtual ~ICallable() {}
};
template <typename T, typename R, typename... Args>
class CallableImpl : public ICallable<R, Args...> {
private:
T callable;
public:
explicit CallableImpl(T callable) : callable(callable) {}
R invoke(Args &&...args) override {
return callable(std::forward<Args>(args)...);
}
};
template <typename Signature> class Function;
template <typename R, typename... Args> class Function<R(Args...)> {
private:
std::unique_ptr<ICallable<R, Args...>> callable;
public:
template <typename T>
Function<R(Args...)>(T &&callable)
: callable(std::make_unique<CallableImpl<T, R, Args...>>(
std::forward<T>(callable))) {}
Function(const Function<R(Args...)> &other) = delete;
Function &operator=(const Function<R(Args...)> &other) = delete;
R operator()(Args &&...args) {
return callable->invoke(std::forward<Args>(args)...);
}
};
int mmax(int a, int b) { return a > b ? a : b; }
int main() {
Function<int(int, int)> f1 = mmax;
std::cout << f1(3, 4) << std::endl;
Function<int(int, int)> f2 = std::function<int(int, int)>(mmax);
std::cout << f2(3, 4) << std::endl;
Function<int(int, int)> f3([](int a, int b) { return a > b ? a : b; });
std::cout << f3(3, 4) << std::endl;
class Callable {
public:
int operator()(int x, int y) { return x > y ? x : y; }
} c;
Function<int(int, int)> f4(c);
std::cout << f4(3, 4) << std::endl;
}
智能指针
std::make_shared 优于 std::shared_ptr<T>(new T) 的原因是:
- 更简洁
std::make_shared会分配一块连续的空间(控制块 + 数据块),locality 更好。而后者的内存空间是分散的。
手写 std::shared_ptr:
template <typename T> class ReferenceCount {
private:
std::atomic<size_t> mRefCount;
T *data;
public:
ReferenceCount(T *data) : data(data), mRefCount(1) {}
void increase() { mRefCount.fetch_add(1); }
void decrease() {
if (mRefCount.fetch_sub(1) == 1) {
delete this;
}
}
size_t count() const { return mRefCount.load(); }
};
template <typename T> class SharedPtr {
private:
T *data;
ReferenceCount<T> *mRefCount;
public:
SharedPtr(T *data) : data(data), mRefCount(new ReferenceCount<T>(data)) {}
SharedPtr(const SharedPtr<T> &other)
: data(other.data), mRefCount(other.mRefCount) {
mRefCount->increase();
}
SharedPtr<T> &operator=(const SharedPtr<T> &other) {
if (mRefCount != other.mRefCount) {
mRefCount->decrease();
mRefCount = other.mRefCount;
data = other.data;
}
mRefCount->increase();
return *this;
}
size_t useCount() const { return mRefCount->count(); }
T *operator->() { return data; }
};
template <typename T, typename... Args> SharedPtr<T> makeShared(Args... args) {
return SharedPtr<T>(new T(std::forward<Args>(args)...));
}
int main() {
SharedPtr<int> a = makeShared<int>(4);
SharedPtr<int> e = makeShared<int>(5);
std::cout << a.useCount() << std::endl;
SharedPtr<int> b = a;
std::cout << a.useCount() << std::endl;
SharedPtr<int> c(a);
std::cout << a.useCount() << std::endl;
b = e;
std::cout << a.useCount() << std::endl;
std::cout << e.useCount() << std::endl;
struct Person {
Person(std::string name, int age) : name(name), age(age) {}
std::string name;
int age;
};
SharedPtr<Person> p = makeShared<Person>("Alice", 32);
std::cout << p->name << ", " << p->age << std::endl;
}
输出:
1
2
3
2
2
Alice, 32
手写 std::any
老样子,使用类型擦除技术(基于特化)。这里的思路我总结下来是这样:std::any 他是不需要指定类型的,比如:
std::any a = 123;
这里实际上只有在构造的时候才会用到类型,对应一个特化的构造函数:
template<typename T>
Any(T val);
例如:
std::any a = 123;
std::any a = std::string("Hello");
将对应两个特化的构造函数。
既然 std::any 不需要指明其存储的类型 T,那么他的所有成员变量一定是和类型 T 无关的,但是我们总要有个地方存这个 T 类型的 value。
所以可以想到,我们定义一个接口,该接口和 T 类型无关,其实现类可以与 T 有关,该实现类是真正存储 T 类型 value 的地方。而 std::any 则可以存储这个接口。
struct IValueHolder {
virtual const std::type_info &type() const = 0;
};
template <typename T> class ValueHolder : public IValueHolder {
private:
T val;
public:
explicit ValueHolder(T val) : val(val) {}
const std::type_info &type() const override { return typeid(val); }
inline const T &value() const { return val; }
};
class Any {
private:
std::unique_ptr<IValueHolder> holder;
public:
template <typename T>
Any(T val) : holder(std::make_unique<ValueHolder<T>>(val)) {}
template <typename T> T AnyCast() {
if (typeid(T) != holder->type()) {
throw std::bad_cast();
}
return static_cast<ValueHolder<T> *>(holder.get())->value();
}
};
int main() {
Any a = 123;
std::cout << a.AnyCast<int>() << endl;
std::cout << a.AnyCast<double>() << endl;
}
输出:
123
libc++abi: terminating due to uncaught exception of type std::bad_cast: std::bad_cast
[1] 25963 abort /Users/lucas/projects/c++/bin/my_test
enum class
- 避免命名空间冲突。
- 可以指定底层存储的类型,
intorlong long… - 可以前置声明。
std::atomic
std::atomic 背后的缓存行锁定(Cache Line Locking)是实现原子操作的关键机制,它依赖于现代 CPU 的缓存一致性协议(如 MESI)和总线锁定(Bus Locking)。当线程对 std::atomic 变量执行原子操作时,CPU 首先尝试通过缓存行锁定实现高效并发:如果该变量所在的缓存行被当前 CPU 独占(Modified 状态),则直接修改并标记为脏;若被其他 CPU 共享(Shared 状态),则通过总线发送 invalidate 信号,迫使其他 CPU 放弃缓存行的所有权,从而获取独占权后执行操作。若缓存行锁定失败(如跨缓存行的操作),CPU 会退化为总线锁定,临时阻塞整个内存总线,确保操作的原子性。这种分级机制平衡了性能与正确性,使 std::atomic 在大多数场景下仅需短暂的缓存行竞争,避免了昂贵的总线锁定开销。
std::atomic<int> flag{0};
int data = 0;
// 线程 A(写端)
data = 42; // 非原子写入
flag.store(1, std::memory_order_release); // release 保证 data 的写入不会重排到之后
// 线程 B(读端)
if (flag.load(std::memory_order_acquire) == 1) { // acquire 保证读到 release 的写入
assert(data == 42); // 一定成功!data 的写入对线程 B 可见
}
std::memory_order_release 保证它之前的所有读写都不会重排到它后面,而 std::memory_order_acquire 又保证了它之后的所有读写不会重排到它前面,这样就形成了 release-acquire 模式,前者保证 flag.Store 之前 data = 42 已经写入;后者保证 flag.load 之后,data = 42 才被读取。
noexcept
std::vector 扩缩容的时候,如果元素的移动构造函数被标记为 noexcept,那它就会大胆地调用移动构造函数,否则就会使用相对更安全的拷贝构造函数。std::sort 的优化类似。
class A {
public:
A() = default;
A(const A &) { std::cout << "copy" << std::endl; }
A(A &&) { std::cout << "move" << std::endl; }
};
int main() {
std::vector<A> aVec;
aVec.emplace_back();
aVec.emplace_back();
}
输出:
copy
将移动构造函数标记为 noexcept,输出:
move
std::enable_shared_from_this
有些时候,我们需要在一个 std::shared_ptr 托管的类的成员函数中,创建它的一个 shared_ptr 新实例,传给某些函数,例如:
class Manager;
class Component {
private:
int *value = new int(3);
Manager *mgr;
public:
Component(Manager *mgr) : mgr(mgr) {}
~Component() {
std::cout << "Deconstruct" << std::endl;
delete value;
}
void DoSomething();
friend class Manager;
};
class Manager {
public:
void Modify(std::shared_ptr<Component> c) { *c->value = 3; }
};
void Component::DoSomething() { mgr->Modify(std::shared_ptr<Component>(this)); }
int main() {
Manager mgr;
auto c = std::make_shared<Component>(&mgr);
c->DoSomething();
}
上述的代码会导致 double free 的问题,正确做法如下:
class Component : public std::enable_shared_from_this<Component> {
...
}
void Component::DoSomething() { mgr->Modify(shared_from_this()); }
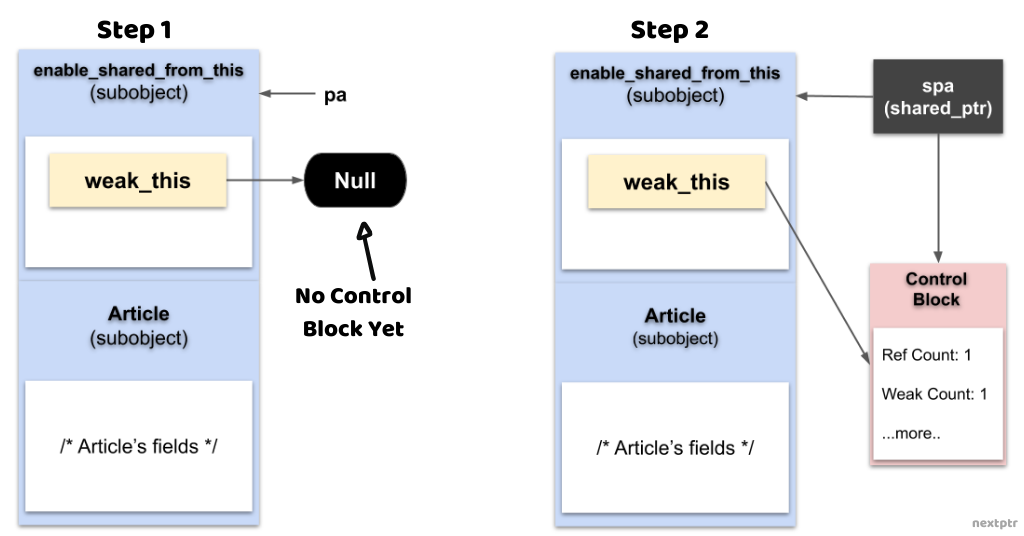
其原理是:构造 Component 的 shared_ptr 的时候,会同时定义一个 weak_ptr 指向 shared_ptr。在调用 shared_from_this 的时候,会由该 weak_ptr 创建对应的 shared_ptr。
注意,此处的 std::enable_shared_from_this<Component> 必须是 public 继承,不然创建 std::shared_ptr 的时候无法正确访问 enable_shared_from_this 中的 weak_ptr。
std::deque 实现原理
std::deque 通常采用 分块存储(Chunked Storage) 的方式实现,即:
由多个固定大小的 “块(Chunks)” 组成,每个块是一个连续的内存数组(称为 “缓冲区” 或 “页”)。
使用一个中央控制结构(如指针数组或动态数组)管理这些块,记录每个块的地址。
这种设计使得:
头尾插入/删除高效(不需要像 vector 那样整体移动元素)。
随机访问(operator[])比 list 快(计算块索引 + 块内偏移)。
典型的 std::deque 实现(如 GCC 的 libstdc++)采用 “Map + Chunks” 结构:
+-------------------+ +-------------------+ +-------------------+
| Chunk 0 (front) | --> | Chunk 1 | --> | Chunk N (back) |
+-------------------+ +-------------------+ +-------------------+
| [0] | [1] | ... | | [0] | [1] | ... | | [0] | [1] | ... |
+-------------------+ +-------------------+ +-------------------+
- Map(控制中心):一个动态数组(如 T**),存储指向各个块的指针。
- Chunk(块):每个块是一个固定大小的数组(如 512B 或 4KB),存储实际数据。